Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
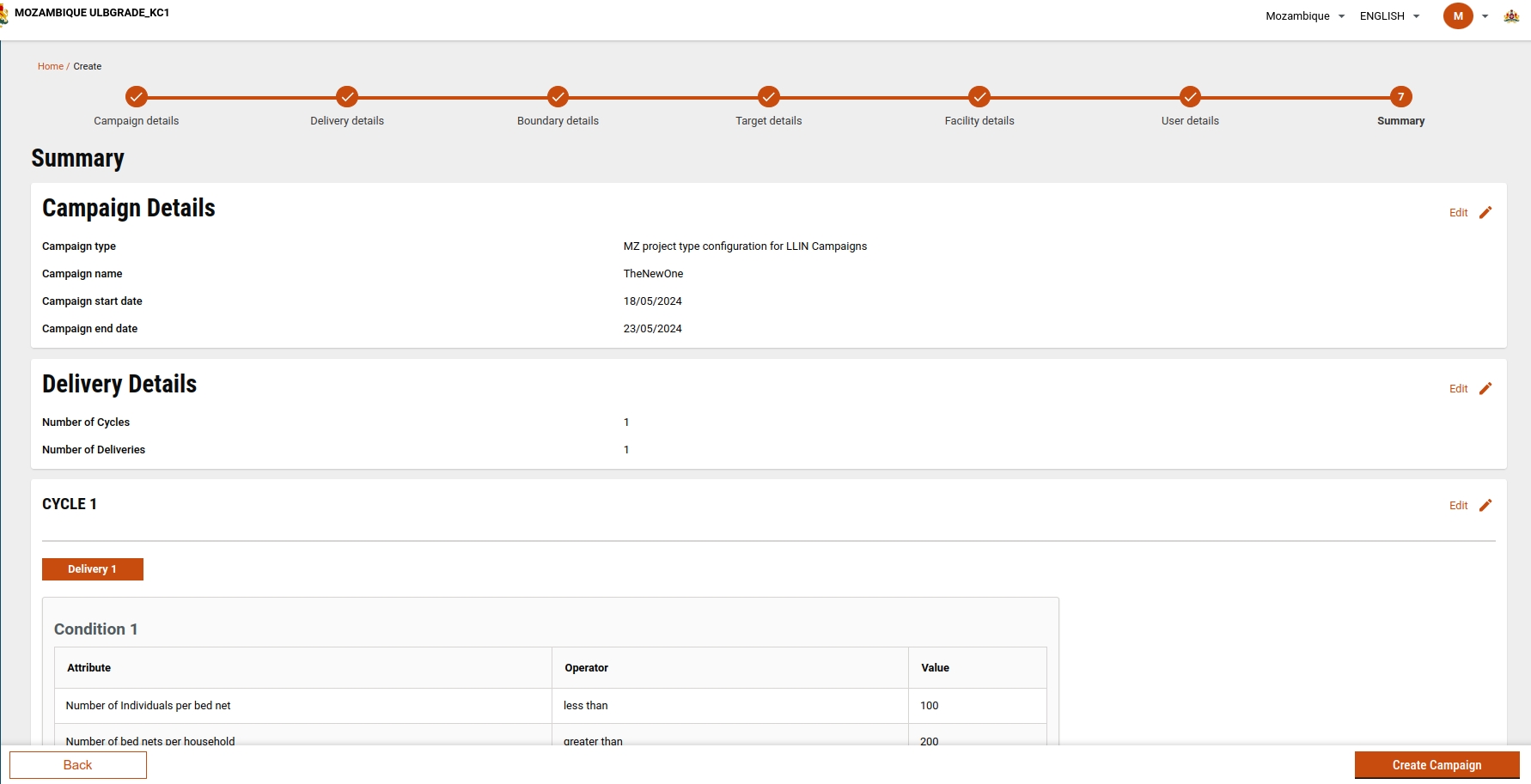
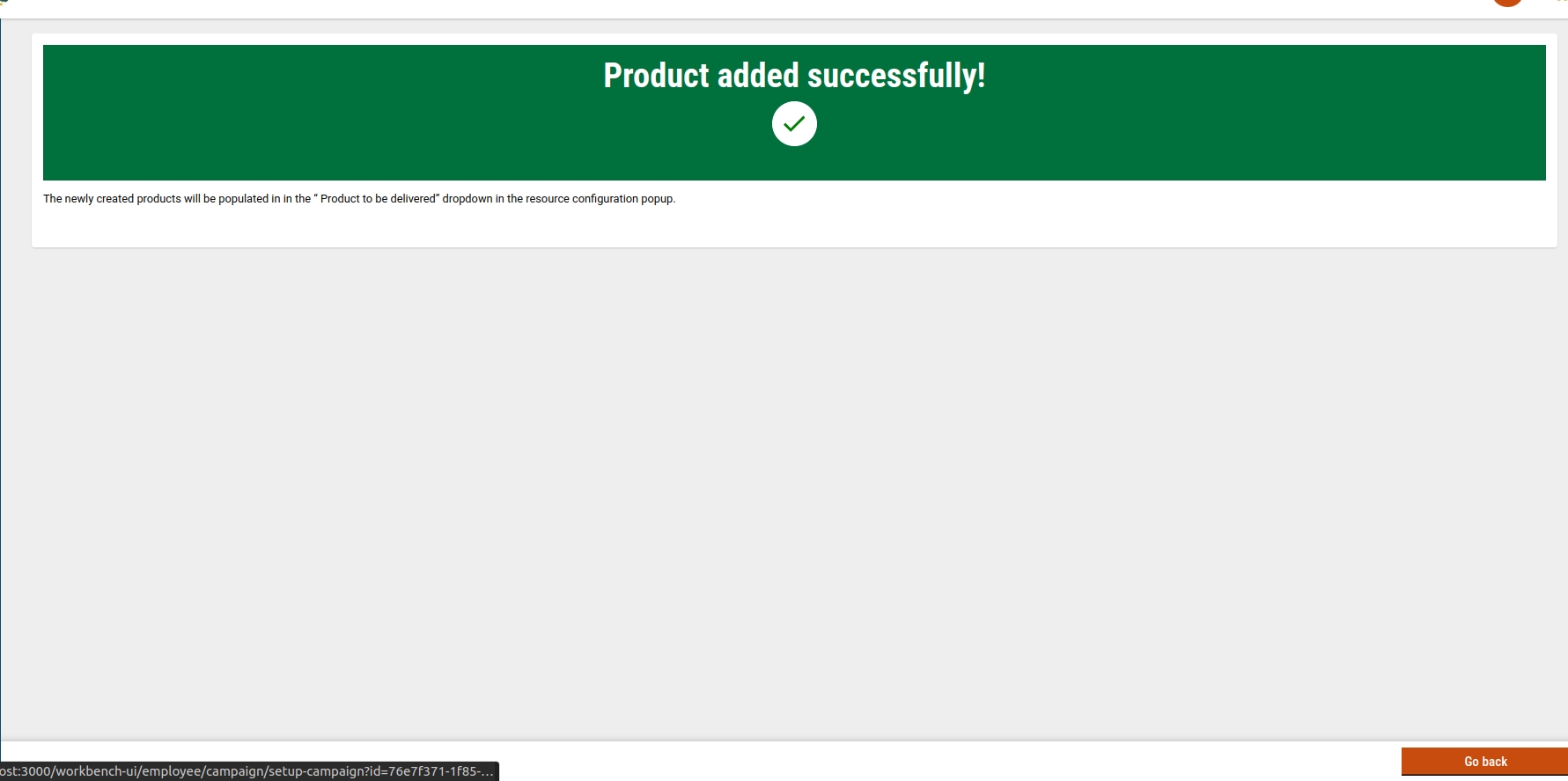
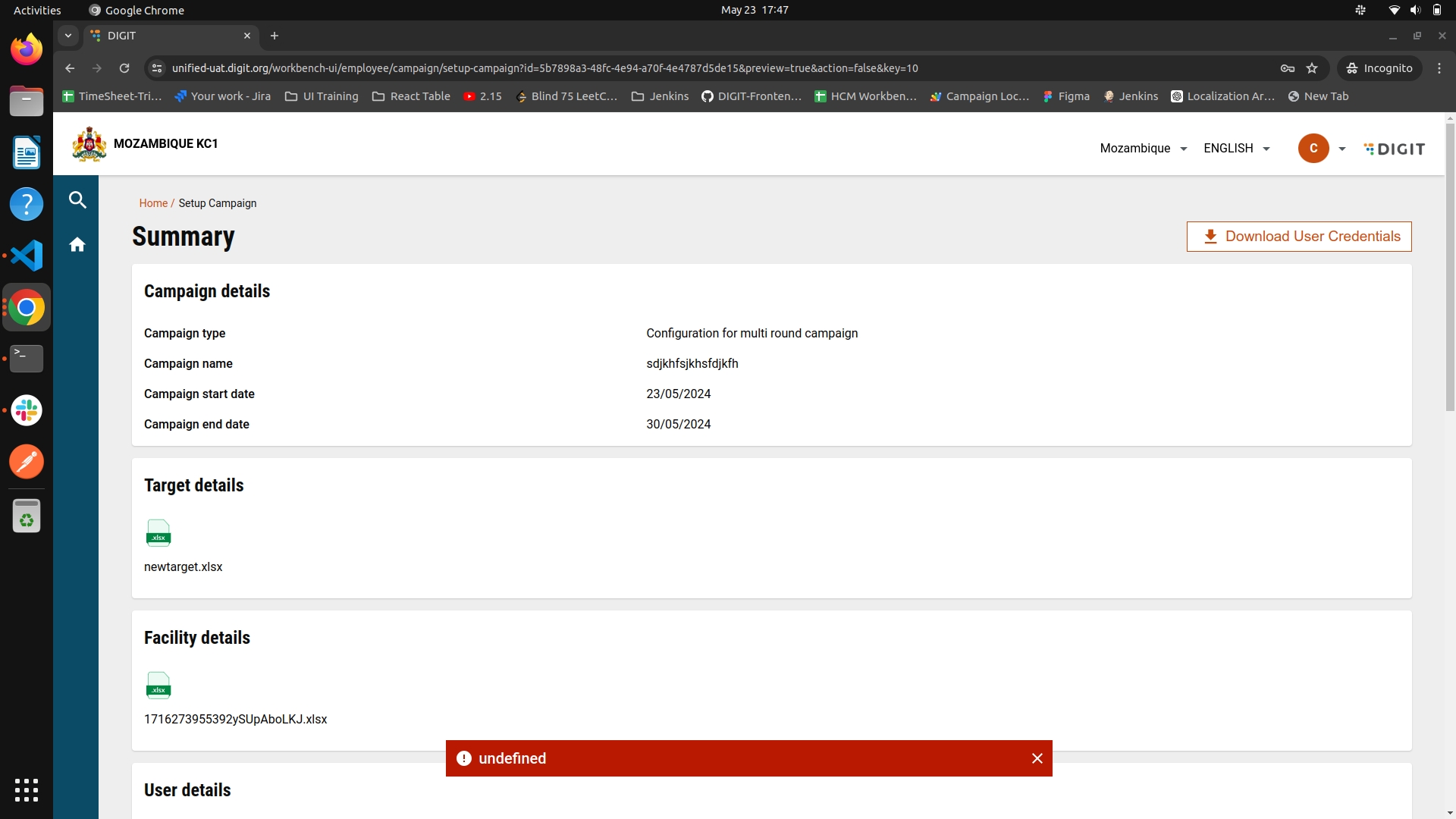
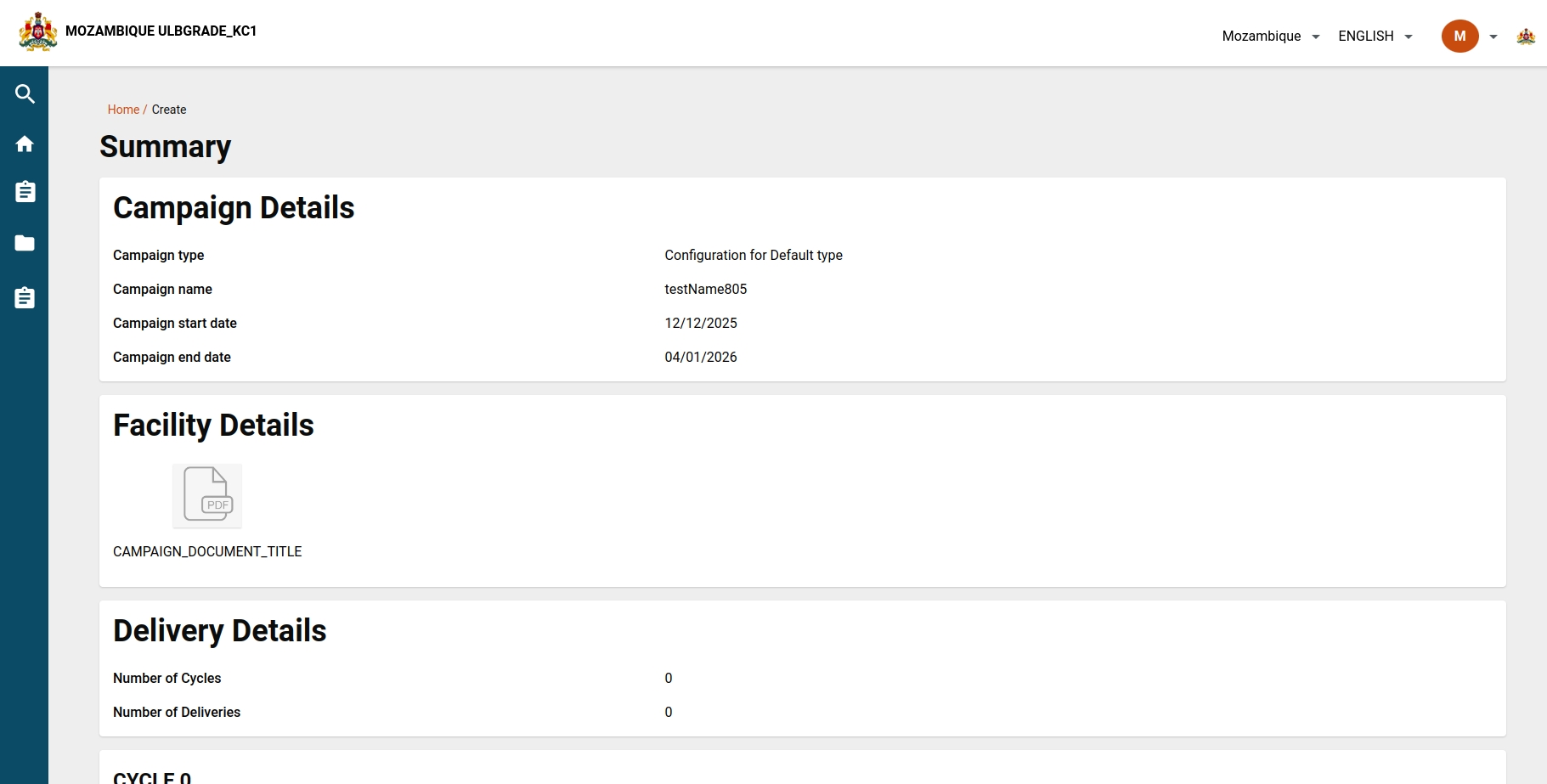
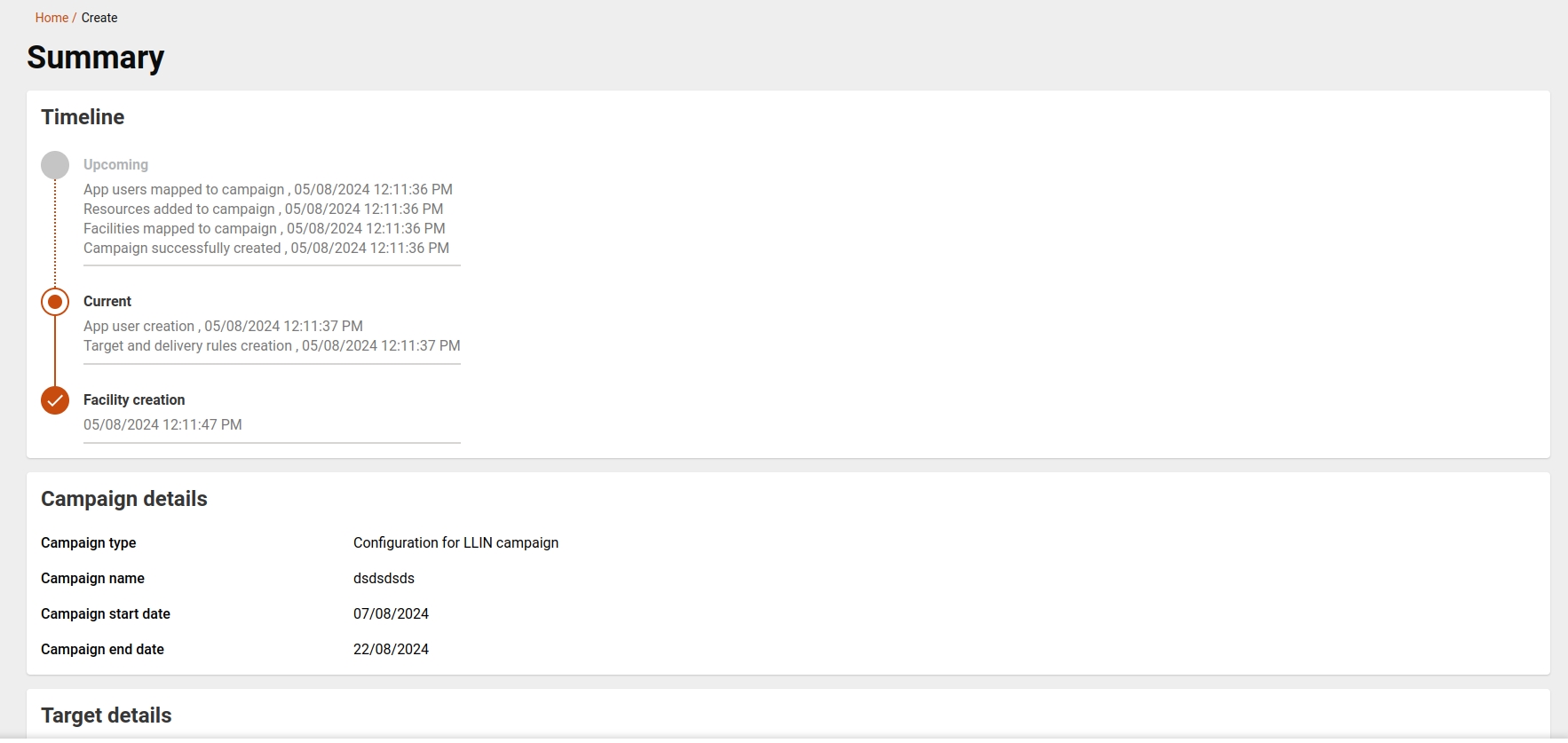
The summary screen provides users with a view of all campaign details entered.
Users can review the entirety of their campaign information. If the campaign status is marked as 'drafted,' users can either edit the existing data or submit it. After submission, the campaign is created, initiating the 'create' action.
For campaigns in a 'draft' status, the summary screen serves as the final step of the campaign setup process, giving users the option to edit or submit the details before finalisation.
If the campaign is successfully created while in the 'draft' status, users are directed to a success screen.
After the API call, the data undergoes restructuring to present delivery rules based on the cycle and delivery details.
For draft status only:
/project-factory/v1/project-type/update
CAMPAIGN_MANAGER
This flow comes in picture if u have parentId present in your request body and that parent campaign should be in created state.
In case parent campaign is present-
Introduced two new columns in Campaign Details table i.e isActive(boolean) and parentId (string)
Validate Parent Campaign(if parentId present)
If actionInUrl is create ,then parentCampaign should be active or isActive of parentCampaign should be true.
If actionInUrl is update, then parentCampaign should be inActive or isActive of parentCampaign should be false.
Validate Boundaries (If Parent Campaign Present)
1. Boundaries array in new Campaign should contain only newly added boundaries and the existing boundaries are fetched from parent Campaign and new boundaries are formed by merging both.
If actionInUrl is create and parentCampaign is present ,call the generate of templates of all three types(boundary, user, facility) .
Create Project -
If new boundaries are selected in update flow , then projects are created only for those newly added boundaries.
If existing targets are updated then update project is called with updated project target mappings.
Edit generated facility and user sheets -
Once you are in update campaign flow, you can edit the existing facility mappings to boundary codes and also make it inactive or active and this would subsequently update the mappings like Project Facility and Project Staff mappings .
Retry Mechanism -
If campaign fails ,we have added retry feature so that it can be restarted from same point where it failed(needs more optimisation).
Update Campaign Object-
Multiple Updates of a Campaign
Once the ongoing campaign is updated and reaches the "Created" state, the updated sheet templates (i.e., Facility, User, and Target) are consolidated back into the format used during the initial "Create" flow.
This ensures that when you attempt to update the campaign again, it will be treated as the first update.
Retry API Payload
Target Upload API
Base URL: project-factory/v1/
Endpoint: /data/_create
Method: POST
Request Structure:
Body Parameters:
RequestInfo: Object Containing RequestInfo
ResourceDetails: Details of a given Resource
type: Type of resource to create (e.g., boundarywithTarget)
tenantId: Tenant
fileStoreId: FileStoreId of Target Upload Sheet
action: Action to perform (e.g., validate for target upload)
hierarchyType: Name of Boundary Hierarchy
campaignId: CampaignId
additionalDetails: Additional details (optional)
Response Structure:
Success Response:
ResponseInfo: Object Containing ResponseInfo
ResourceDetails: Details of the created resource
Flow:
Client Initiates Request:
The client sends a POST request to /data/_create endpoint with action: validate.
Validation of Request:
Resource Details Validation:
Check if request.body.ResourceDetails exists and is not empty.
Throw a validation error if missing or empty with the message "ResourceDetails is missing or empty or null".
Schema Validation:
Validate request.body.ResourceDetails against createRequestSchema.
Hierarchy Type Validation:
Validate hierarchyType in request.body.ResourceDetails using validateHierarchyType function.
Tenant ID Validation:
Ensure that request.body.ResourceDetails.tenantId matches request.body.RequestInfo.userInfo.tenantId.
Throw a validation error if they do not match with the message "tenantId is not matching with userInfo".
Different Tab Headers Validation:
Validate whether headers are according to the template across all tabs of different districts.
Target Sheet Validation:
All validations will be on Sheets other than the ReadMe Sheet and Boundary Data Sheet.
Immediate validations:
District Tabs Validation:
Validate whether all district tabs are present in the Target Sheet uploaded.
Empty Sheet Validation:
Throw a validation error if any Target Sheet is empty.
Root (District) level boundary validation:
Throw a validation error if the root column (District) is empty in any row.
Validations for each row:
Boundary Codes Validation:
Check for missing or empty boundary codes in any row of any sheet.
Check for boundary code columns to be of type string.
Check for the presence of more than one boundary code in a given row of a given Target Sheet.
Check for duplicacy of the boundary code within the given Target Sheet.
Boundary Targets Validation:
Ensure that Target values are not missing and are positive numbers less than 1 Million.
Generate API for Boundary
Base URL: project-factory/v1/
Endpoint: /data/_generate
Method: POST
Request Structure:
Body Parameters:
RequestInfo: Object containing RequestInfo
Query Parameters:
tenantId: Tenant
type: Type of Resource (e.g., boundary)
forceUpdate: Boolean type (either true or false)
hierarchyType: Name of Boundary Hierarchy
campaignId: CampaignId
Response Structure:
Success Response:
Client Initiates Request:
The client initiates a dataGenerate request to the Project Factory Service.
Validation of Request:
Schema Validation: Validate against generateRequestSchema.
Tenant ID Validation: Ensure tenantId matches in query and RequestInfo.userInfo.
Force Update: Default to "false" if missing.
Hierarchy Type Validation: Validate hierarchyType for the tenantId.
Processing of Generate Request:
Fetch Data from DB:
Retrieve data using getResponseFromDb(request).
Modify Response Data:
Modify the fetched data with getModifiedResponse(responseData).
Generate New Entry:
Create a new entry with getNewEntryResponse(request).
Expire Old Data:
Update the status of old data to expired using getOldEntryResponse(modifiedResponse, request).
Persist Data Changes:
Call updateAndPersistGenerateRequest(newEntryResponse, oldEntryResponse, responseData, request).
Purpose:
If forceUpdate is true and data exists: Mark existing data as expired and create new data.
No data exists or force update is true: Generate new data.
If forceUpdate is false and data exists: Return the old data.
Boundary Data Processing:
Generate new Boundary Data:
Fetch Boundary Relationships.
If no boundary is found, generate an empty boundary sheet.
Fetch Filters from CampaignId and generate Boundary Data based on those Filters.
If Filters is null, it will generate the whole Boundary Data.
After the Boundary Sheet has been generated, append the ReadMeSheet.
Generate different tabs based on any boundary level configured (here District).
Generating Different Boundary Templates based on Campaign Type
Fetch configurable columns from mdms present for each campaign type from schema -[HCM-ADMIN-CONSOLE.adminSchema].
Here is a sample data from the given schema having configurable columns for Campaign SMC-
Handle Error:
Update status to failed, add error details, log the error, and produce a message to the update topic.
Downloading the generated boundary template through /data/_generate API:
One can get the filestoreId through the /data/_download API which will fetch from db using the id from the response of /data/_generate API.
Note:
Downloaded Template will have one ReadMe sheet, one Boundary Data Tab, and all other tabs on a number of unique districts(or whichever level configured).
/project-factory/v1/project-type/fetch-from-microplan
This document describes the web flow for updating an existing campaign by integrating the existing microplan with the console. This process involves the integration of several backend services to update the data in the facility, target, and user sheet in the existing campaign object.
Core Services
Plan Service
Census Service
Initiating Request: The request body for the microplan integration will be:
Validations:
This request validates whether the campaignId and planConfigurationId exist in the system or are invalid.
Facility Sheet Updation:
The process begins by searching for the facility associated with the planConfigurationId, which provides details about the facility code and the linked service boundaries. Next, a facility sheet is generated for the campaign. Once the facility sheet is obtained, the service boundaries are populated within the sheet where the specific facility code is present.
After completing the facility sheet, it is validated using the Validate API. Once validation is successful, the campaign object is updated with the new facilityId and resourceId.
We get the data to fill in this sheet from plan-service/plan/facility/_search where data is like this and map the facilityId to the serviceBoundaries.
Target Sheet Updation:
The process begins by performing a plan census search using the planConfigurationId, which retrieves details about the boundary code and its associated census data. After obtaining the mapping between the boundary code and the linked census, a target sheet of type boundary is generated for the campaign and hierarchy by invoking the Generate API.
A predefined MDMS schema ensures accurate mapping between the headers in the target sheet and the fields in the data. This schema acts as a blueprint, defining the correspondence between the data fields and their respective headers in the generated sheet. For this sheet, we get the data from census search API where the data looks like this:
The sample data for filling the target sheet is:
Here, the type of the target sheet is constructed as Target-<projectType> of the campaign.
to: This specifies the key to be extracted from the census object.
from: These are the keys representing the headers that need to be enriched in the generated sheet.
This mapping ensures that the data from the census object is correctly aligned and populated into the appropriate headers in the target sheet.
After populating the worksheet with data from the census objects, the file is uploaded to the filestore. Next, the sheet is validated using the Validate API with the type boundaryWithTarget. Once the validation is completed, the campaign object is updated with the newly generatedfilestoreId and resourceId.We get data from census search as follows:
User Sheet Updation:
The process begins by fetching the plan associated with the planConfigurationId and retrieving the boundaries from the campaign details, specifically those of type LOCALITY. Next, for each locality, the count of all roles is obtained from the plan search response. This role count is then enriched in the corresponding sheet for that locality.
To map the roles and their requirements for determining the role count in the plan facility response, the predefined MDMS schema for the target is utilized. In this schema:
to: Represents the role to be mapped.
from: Specifies an array of keywords that must be present in the key to identify the role.
This ensures accurate and efficient mapping and population of role-related data in the sheet. Also used -
Added a field consolidateUsersAt in the schema to filter for boundaries based on a particular hierarchy; Example: LOCALITY Sample Data:
Sample MDMS data:
After populating the sheet with the appropriate information, the sheet is validated by calling the Validate API with the type userWithBoundary. Once the validation is successful, the campaign object is updated accordingly. We get the data to fill in this sheet from this API:
This document outlines the process for updating an existing campaign by integrating a microplan through the admin console. It involves validating the campaignId and planConfigurationId and updating the facility, target, and user sheets using data from backend services.
Facility Sheet: Generated using facility details from the planConfigurationId, enriched with service boundaries, validated, and updated in the campaign object.
Target Sheet: Created by mapping census data to boundary codes using the MDMS schema. The sheet is populated, validated, uploaded, and updated in the campaign object.
User Sheet: Locality boundaries are fetched, role counts are calculated and enriched using the MDMS schema, and the sheet is validated before updating the campaign object.
This integration ensures accurate, automated updates and efficient campaign management.
Here are the articles in this section:
This allows users to fill in all the campaign details and create a new campaign.
Click on the following links to learn more:
Below are the configurations needed for successfully setting up the campaign module:
citymodule needed to run campaign module in an environment:
Link: https://github.com/egovernments/egov-mdms-data/blob/UNIFIED-QA/data/mz/tenant/citymodule.json
roleactions config needed for the user for all campaign access
actionTest config needed for sidebar action and user access for services
To enable action in the sidebar, add navigationUrl and path to the object:
Refer to the below ID's link in QA:
roles need to be added in roles
Boundary Schema config needs to be added for boundary sheet validation:
Facility Schema config needs to be added for facility sheet validation:
User schema config needs to be added for user sheet validation:
A hierarchy config needs to be added to define a lowset hierarchy in boundary selection:
Global configuration needs to be added to environments.
Helm chart needs to be added in DevOps.
Refer here to learn more about the setup environment.
rainmaker-common
For all common screen localisation messages like login, homepage, sidebar
rainmaker-campaignmanager
For all console-related screens localisation messages
rainmaker-hcm-admin-schemas
For all upload schemas like target, facility, user
boundary-${BOUNDARY_HIERARCHY_TYPE}
For boundary type localisations, we get this BOUNDARY_HIERARCHY_TYPE from the MDMS
Project-factory assists users in generating the seed data essential for the campaign creation process in DIGIT HCM and in establishing relationships between all resources. The Project Factory Service manages project-type campaigns by handling the creation, updating, searching, and campaign setup processes. This documentation details the available APIs, their endpoints, request and response structures, and internal processing flows.
Knowledge of JavaScript (preferably ES6).
Knowledge of Git or any version control system.
Knowledge of RESTful web services.
Knowledge of the Kafka and Postgres.
Knowledge of eGov-mdms service, eGov-persister, eGov-idgen, eGov-indexer, and eGov-user will be helpful.
project-factory/v1/
TO DO add other information
Swagger :
Configure the role CAMPAIGN_MANAGER for project-factory in the ‘ACCESSCONTROL-ROLES’ module.
Configure the action id(s) with the corresponding role code ‘ACCESSCONTROL-ROLEACTIONS’ module.
For Project Factory Service Role-Action mappings are as follows in the Dev environment.
API EndPoints
Roles
/project-factory/v1/project-type/create
CAMPAIGN_MANAGER
/project-factory/v1/project-type/update
CAMPAIGN_MANAGER
/project-factory/v1/project-type/search
CAMPAIGN_MANAGER
/project-factory/v1/data/_create
CAMPAIGN_MANAGER
/project-factory/v1/data/_search
CAMPAIGN_MANAGER
/project-factory/v1/data/_generate
CAMPAIGN_MANAGER
/project-factory/v1/data/_download
CAMPAIGN_MANAGER
Additional APIs being used are:
API EndPoints
Roles
/boundary-service/boundary-hierarchy-definition/_search
CAMPAIGN_MANAGER
boundary-service/boundary-relationships/_search
CAMPAIGN_MANAGER
/product/variant/v1/_search
CAMPAIGN_MANAGER
/product/v1/_search
CAMPAIGN_MANAGER
/product/v1/_create
CAMPAIGN_MANAGER
/product/variant/v1/_create
CAMPAIGN_MANAGER
Configure all the MDMS data for project factory service as done in the QA environment.
Data to configure :
Attribute Config
Boundary Schema
Delivery Config
Facility Schema
Gender Config
Mail Config
Operator Config
Product Type
User Schema
Refer to the following:
https://github.com/egovernments/egov-mdms-data/tree/UNIFIED-QA/data/mz/health/hcm-admin-console
Make sure the id format is configured in the ‘IdFormat.json’ file of the ‘common-masters’ module.
Below is what is currently configured in the QA environment.
Environment variables Below are the variables that should be configured well before deployment of the project factory service build image.
Add these ‘db-host’,’db-name’,’db-url’,’domain’ and all the digit core platform services configurations (Idgen ,persister, filestore, etc.) in respective environments yaml file.
Add project factory service related environment variables’ value like the way it's done in the QA environment yaml file. (Search for project-factory)
Heath-hrms, health-project, health-individual and facility should have specified heap and memory limits as mentioned below
Make sure to add the DB(Postgres and flyway) username & password in the respective environment secret yaml file the way it's done here.
Make sure to add the digit core services related secrets are configured in the respective environment secret file the way it's done here.
Click here for localisation details.
Click here to get the Postman Collection
The documentation details the API endpoints for creating, updating, and searching project type campaigns. It includes request and response structures, validation steps, and flow diagrams.
POST /project-type/create
RequestInfo: Object containing RequestInfo.
CampaignDetails: Object containing the details of the campaign to be created.
tenantId: Tenant identifier.
hierarchyType: Type of hierarchy.
action: Action type (create or draft).
boundaries: Array of boundaries.
resources: Array of resources.
projectType: Type of the project.
deliveryRules: Array of delivery rules.
Additional request info
ResponseInfo: Object containing ResponseInfo.
CampaignDetails: The created campaign details.
The client initiates a createCampaign request to the Project Factory Service.
If the action is 'create':
The Project Factory Service validates the request schema.
It also validates the uniqueness of the campaign name in the database.
If the campaign name exists, an error is thrown.
If the action is 'draft':
The Project Factory Service validates the request schema.
It also validates the uniqueness of the campaign name in the database.
If the campaign name exists, an error is thrown.
For both 'create' and 'draft' actions:
The Project Factory Service validates the request for hierarchy type and boundaries with the Boundary Service.
It validates the request for project type code from MDMS.
If the action is 'create':
The Project Factory Service validates the request for data resources.
It enriches the CampaignDetails and sets the status to 'creating'.
The CampaignDetails are persisted in the database.
For each resource data, the Project Factory Service creates resources through the /project-factory/v1/data/_create API.
It enriches boundaries for project creation and creates projects for each boundary with the Health Project Service.
The enriched CampaignDetails are persisted in the database.
The CampaignDetails object is sent to a Kafka topic for project mappings.
If the campaign status is not "created", project mappings are performed through the /project-factory/v1/project-type/createCampaign API and the status is updated to 'created'.
If the campaign status is already 'created', an error is thrown, and the status is updated to 'failed'.
If the action is 'draft':
The CampaignDetails are enriched, and the status is set to 'drafted;.
The enriched CampaignDetails are persisted in the database.
The Project Factory Service sends the response back to the client.
POST /project-type/update
RequestInfo: Object containing RequestInfo.
CampaignDetails: Object containing the details of the campaign to be updated.
id: Unique identifier of the campaign.
tenantId: Tenant identifier.
hierarchyType: Type of hierarchy.
action: Action type (create or draft).
boundaries: Array of boundaries.
resources: Array of resources.
projectType: Type of the project.
deliveryRules: Array of delivery rules.
ResponseInfo: Object containing ResponseInfo.
CampaignDetails: The updated campaign details.
The ProjectFactoryService receives an updateCampaign request from the Client.
The received request schema is validated to ensure it matches the expected format.
The system checks if the campaign specified in the request exists in the database.
If boundaries are different from campaign in db, call:
Facility template generate
User template generate
Target template generate
If delivery conditions are different, call:
Target template generate
If the campaign exists, the system checks its status in the database.
If the campaign status is 'drafted':
Validate Boundaries: Validate the request for hierarchyType and boundaries.
Validate Project Type: It validates the request for project type code from MDMS.
Enrich Campaign Details: Enrich the campaign details and set the status to 'updating'.
Update Campaign Details: Update the campaign details in the database.
Update Resource Data: Update each resource data associated with the campaign through the /project-factory/v1/data/_update API.
Enrich Boundaries: Enrich the boundaries for the project update.
Update Projects: Update projects associated with each boundary.
Persist Changes: Persist the updated campaign details in the database.
Send to Kafka Topic: Send the updated CampaignDetails object to the Kafka topic for project mappings.
Listen to Kafka: Listen for updates from the Kafka topic to get the updated CampaignDetails object for project mappings.
If the campaign status is not 'created':
Do project mapping through /project-factory/v1/project-type/createCampaign API.
Enrich the CampaignDetails and set the status to 'created'.
Update the CampaignDetail in the database.
If the campaign status is 'created':
Throw an error indicating that the project is already mapped for this campaign.
Enrich the CampaignDetails and set the status to 'failed'.
Update the CampaignDetail in the database.
If the campaign status is not 'drafted', the system throws an error indicating that only drafted campaigns can be updated.
The ProjectFactoryService sends a response to the Client based on the outcome of the update operation.
POST /project-type/search
RequestInfo: Object containing RequestInfo.
CampaignDetails: Object containing the search criteria for campaigns.
tenantId: Tenant identifier.
ids: Array of campaign IDs to search for.
startDate: The start date for the search.
endDate: End date for the search.
projectType: Type of the project.
campaignName: Name of the campaign.
status: Status of the campaign.
createdBy: Creator of the campaign.
campaignNumber: Number of the campaign.
campaignsIncludeDates: Flag to include campaigns based on dates.
pagination: Object containing pagination settings.
limit: Maximum number of results to return.
offset: Offset for paginated results.
sortOrder: Sort order for results (asc/desc).
sortBy: Field to sort results by.
ResponseInfo: Object containing ResponseInfo details.
CampaignDetails: Array containing details of matching campaigns.
totalCount: Total number of matching campaigns.
The client sends a searchCampaign request to the Project Factory Service.
The Project Factory Service validates the request schema and search criteria.
The Project Factory Service constructs a search query based on the provided criteria.
It checks if there are specific search fields like start date, end date, campaign name, etc.
Depending on the campaignsIncludeDates flag, the service adjusts the search conditions accordingly.
If campaignsIncludeDates is true:
It shows only those campaigns whose start date is on or before the provided start date and whose end date is on or after the provided end date.
If campaignsIncludeDates is false:
It shows only those campaigns whose start date is on or after the provided start date and whose end date is on or before the provided end date.
The service executes the constructed query to retrieve matching campaign details from the database.
The Project Factory Service sends the response back to the client.
The response contains the matching campaign details along with the total count, if applicable.
POST /project-type/getProcessTrack
campaignId: Unique ID of the campaign.
Success Response:
ResponseInfo: Object containing ResponseInfo details.
processTrack: Array containing process tracks of the matching campaign.
Client Initiates Request
The client sends a request to retrieve process tracks for a specific campaign by providing the campaignId.
Validation of Request
The Project Factory Service validates the provided campaignId to ensure it meets the expected format and constraints.
Fetch Process Tracks
The Project Factory Service constructs a query to fetch process tracks associated with the provided campaignId.
The service executes the query against the database to retrieve the process tracks.
Response
The Project Factory Service formats the retrieved process tracks and packages them into the response.
The response includes the ResponseInfo and an array of processTrack details.
Send Response to Client
The Project Factory Service sends the response back to the client containing the process track details for the specified campaign.
processTrackTypes (Steps)This defines various types of process tracks, each representing a specific stage or action in the campaign creation process. These types can be used to categorize and identify different steps or activities within the campaign workflow. Here's what each type represents:
validation: Represents the validation stage of the campaign creation process, where data or conditions are checked for correctness.
triggerResourceCreation: Indicates the step where resources are created based on triggers or conditions.
facilityCreation: Refers to the creation of facilities or resources required for the campaign.
staffCreation: Involves the creation of staff members necessary for the campaign.
targetAndDeliveryRulesCreation: Represents the creation of rules related to targets and delivery mechanisms (project creation step).
confirmingResourceCreation: Involves confirming that resources have been successfully created.
prepareResourceForMapping: The stage where resources are prepared for mapping to projects.
validateMappingResource: Represents the validation of resources after they have been mapped.
staffMapping: Involves mapping staff to projects.
resourceMapping: Represents the mapping of various resources to projects.
facilityMapping: Refers to mapping facilities to projects.
campaignCreation: Represents the creation of the campaign itself (final step).
error: Indicates that an error occurred during the campaign creation process.
processTrackStatusesThis object defines different statuses that a process track can have, reflecting the state or progress of a particular step in the campaign creation process. Here are the statuses and their meanings:
inprogress: Indicates that the process or task within the campaign creation process is currently ongoing and has not yet been completed.
completed: Represents that the process or task within the campaign creation process has been successfully finished.
toBeCompleted: Refers to processes or tasks within the campaign creation process that are scheduled or pending completion in the future.
failed: Signifies that the process or task within the campaign creation process encountered an error or failed to execute as intended.
Generate API for Boundary with Latitude and Longitude
Generation API for Boundary
Base URL: project-factory/v1/
Endpoint: /data/_generate
Method: POST
Request Structure:
Body Parameters:
RequestInfo: Object containing RequestInfo
Query Parameters:
tenantId: Tenant
type: Type of Resource (e.g., boundaryManagement)
forceUpdate: Boolean type (either true or false)
hierarchyType: Name of Boundary Hierarchy
campaignId: default (Mandatory)
Response Structure:
Success Response:
Client Initiates Request:
The client initiates a dataGenerate request to the Project Factory Service.
Validation of Request:
Schema Validation: Validate against generateRequestSchema.
Tenant ID Validation: Ensure tenantId matches in query and RequestInfo.userInfo.
Force Update: Default to "false" if missing.
Hierarchy Type Validation: Validate hierarchyType for the tenantId.
Processing of Generate Request:
Fetch Data from DB:
Retrieve data using getResponseFromDb(request).
Modify Response Data:
Modify the fetched data with getModifiedResponse(responseData).
Generate New Entry:
Create a new entry with getNewEntryResponse(request).
Expire Old Data:
Update the status of old data to expired using getOldEntryResponse(modifiedResponse, request).
Persist Data Changes:
Call updateAndPersistGenerateRequest(newEntryResponse, oldEntryResponse, responseData, request).
Purpose:
If forceUpdate is true and data exists: Mark existing data as expired and create new data.
No data exists or force update is true: Generate new data.
If forceUpdate is false and data exists: Return the old data.
Boundary Data Processing:
Generate new Boundary Data:
Fetch Boundary Relationships.
If no boundary is found, generate an empty boundary sheet.
Fetch Filters from CampaignId and generate Boundary Data based on those Filters.
If Filters is null, it will generate the whole Boundary Data.
After the Boundary Sheet has been generated, append the ReadMeSheet.
Generate different tabs based on any boundary level configured (here District).
Generating Different Boundary Templates based on Campaign Type
Fetch configurable columns from mdms present for each campaign type from schema -[HCM-ADMIN-CONSOLE.adminSchema].
Here is a sample data from the given schema having configurable columns for Campaign SMC-
Handle Error:
Update status to failed, add error details, log the error, and produce a message to the update topic.
Downloading the generated boundary template through /data/_generate API:
One can get the filestoreId through the /data/_download API which will fetch from db using the id from the response of /data/_generate API.
Note:
Downloaded Template will have one ReadMe sheet, one Boundary Data Tab, and all other tabs on a number of unique districts(or whichever level configured).
Generate API for Boundary by using GeoJsons
Generation API for Boundary
Base URL: project-factory/v1/
Endpoint: /data/_generate
Method: POST
Request Structure:
Body Parameters:
RequestInfo: Object containing RequestInfo
Query Parameters:
tenantId: Tenant
type: Type of Resource (e.g., boundaryManagement)
forceUpdate: Boolean type (either true or false)
hierarchyType: Name of Boundary Hierarchy
campaignId: default (Mandatory)
Success Response:
In this API the filestore ID will be the ID the geoJson file which will be:
Client Initiates Request:
The client initiates a dataGenerate request to the Project Factory Service.
Validation of Request:
Schema Validation: Validate against generateRequestSchema.
Tenant ID Validation: Ensure tenantId matches in query and RequestInfo.userInfo.
Force Update: Default to "false" if missing.
Hierarchy Type Validation: Validate hierarchyType for the tenantId.
Processing of Generate Request:
Fetch Data from DB:
Retrieve data using getResponseFromDb(request).
Modify Response Data:
Modify the fetched data with getModifiedResponse(responseData).
Generate New Entry:
Create a new entry with getNewEntryResponse(request).
Expire Old Data:
Update the status of old data to expired using getOldEntryResponse(modifiedResponse, request).
Persist Data Changes:
Call updateAndPersistGenerateRequest(newEntryResponse, oldEntryResponse, responseData, request).
Purpose:
If forceUpdate is true and data exists: Mark existing data as expired and create new data.
No data exists or force update is true: Generate new data.
If forceUpdate is false and data exists: Return the old data.
Boundary Data Processing:
Generate new Boundary Data:
Fetch Boundary Relationships.
If no boundary is found, generate an empty boundary sheet.
Fetch Filters from CampaignId and generate Boundary Data based on those filters.
If the filter is null, it will generate the whole Boundary Data.
After the Boundary Sheet has been generated, append the ReadMeSheet.
Generate different tabs based on any boundary level configured (here District).
Generating Different Boundary Templates based on Campaign Type
Fetch configurable columns from mdms present for each campaign type from schema - (HCM-ADMIN-CONSOLE.adminSchema).
Here is a sample data from the given schema having configurable columns for the SMC campaign:
Handle Error:
Update status to failed, add error details, log the error, and produce a message to the update topic.
Downloading the generated boundary template through /data/_generate API:
One can get the filestoreId through the /data/_download API which will fetch from db using the id from the response of /data/_generate API.
After successful generation, the sheet you will get from filestoreId will be:
Note: The downloaded template will have one ReadMe sheet, one Boundary Data tab, and all other tabs on a number of unique districts (or whichever level is configured).
The "Setup Campaign" feature facilitates the creation of a campaign using an approved microplan. It ensures that only authorized users can initiate the setup process, generates required campaign data, and integrates with external APIs to fetch user, facility, and target data.
Role Required: MICROPLAN_CAMPAIGN_INTEGRATOR
Validation Logic:
Only users with the above role can select an approved microplan to initiate the campaign setup.
If the user lacks the role, access to the feature is denied with a proper error message.
Input: Approved microplan object.
Steps:
Extract the base campaign object from the selected microplan.
Create a new campaign object by cloning the base campaign object with the following updates:
Add unique identifiers (campaignId, createdBy).
Set the campaign status to draft.
Save the new campaign object to the backend.
Trigger: After updating the campaign object with selected boundaries, it gets auto-generated from Backend
Steps:
Automatically generate empty templates for the campaign, including:
User assignments.
Facility data placeholders.
Target data placeholders.
API Endpoint: project-factory/v1/project-type/fetch-from-microplan
Steps:
Call the Microplan API to fetch:
User data.
Facility data.
Target data.
Populate the empty templates with the fetched data.
Save the updated templates back to the backend.
Purpose: Monitor the progress of data population and transition to the next step once completed.
Steps:
The UI triggers a periodic call to the campaignSearch endpoint:
API Endpoint: /campaign-search
Parameters: campaignId.
Check the status of the campaign:
If Completed:
Navigate the user to the Setup Campaign page.
If In Progress:
Re-trigger the data fetch from Microplan API to ensure completion.
Continue polling.
Steps:
Transition the user to the Setup Campaign page.
Pass the necessary campaign data as route parameters or via state management.
The documentation details APIs for creating, searching, generating, and downloading data, including request/response structures, flows, and error handling.
Endpoint: /data/_create
Method: POST
Body Parameters:
RequestInfo: Object containing request information.
Resource Details: Object containing the details of the resource to be created or validated.
type: Type of resource (boundary, facility, user, boundaryWithTarget).
tenantId: Tenant identifier.
fileStoreId: File store identifier.
action: Action type (create or validate).
hierarchyType: Type of hierarchy.
campaignId: Campaign identifier.
additionalDetails: Additional details object (optional).
Success Response:
- ResponseInfo: Object containing response information.
- ResourceDetails: Array containing the detail objects of the created or validated resource.
Client Initiates Request: The client sends a createData request to the Project Factory service.
Validation of Request: The Project Factory service validates the request schema and the provided resource details.
Processing the Request:
If action is 'create':
Enrich resource details, set status to "data-accepted", and persist in the database.
Further creation process happens in the background.
After successful creation, set the status to 'completed' and persist resource details in the database.
If action is 'validate':
Enrich resource details, set the status to "validation-started", and persist in the database.
Further creation process happens in the background.
If file data is invalid, set the status to 'invalid' and persist in the database.
After successful creation, set the status to 'completed' and persist resource details in the database.
Fail case: If validation or creation fails, set the status to 'failed' and persist in the database with the error cause in additional details.
Response: The Project Factory service sends the response back to the client containing the resource details and status.
The getSheetData function retrieves and processes data from an Excel sheet, validating the structure according to the configuration provided in createAndSearchConfig. The key part of this process is the parseArrayConfig.parseLogic configuration, which specifies how to parse and validate the columns in the sheet. Here's a detailed explanation of how the function works, including the parsing logic:
The parseArrayConfig.parseLogic configuration specifies how each column in the sheet should be processed. Here's how the parsing logic works:
Each column configuration specifies:
sheetColumn: The column letter in the sheet.
sheetColumnName: The expected name of the column in the sheet.
resultantPath: The path where the value will be stored in the resultant JSON.
type: The expected type of the value (e.g., string, number, boolean).
conversionCondition: Optional conditions for converting values.
During the validation step, the function checks that the first-row value matches the expected column name.
When mapping the rows to JSON, the function uses the resultantPath to place the values in the correct location in the JSON object. It converts values according to the specified type and conversionCondition.
For a column configuration with type: "boolean" and conversionCondition, the function would convert "Permanent" to true and "Temporary" to an empty string.
In summary, the getSheetData function retrieves and processes data from an Excel sheet, validating the structure and content according to the createAndSearchConfig configuration. The parseArrayConfig.parseLogic configuration specifies how each column should be validated and processed into the resultant JSON format.
Endpoint: /data/_search
Method: POST
RequestInfo: Object containing request information.
SearchCriteria: Object containing search criteria.
id: (Optional) ID of the resource.
tenantId: Tenant identifier.
type: (Optional) Type of the resource (boundary, facility, user, boundaryWithTarget).
status: (Optional) Status of the resource.
ResponseInfo: Object containing response information.
ResourceDetails: Array containing the details object of the searched resource.
Client Request: The client sends a POST request to /data/_search.
Request Content: Includes RequestInfo and SearchCriteria.
Validation: The server validates request structure and content.
Response Creation: The server creates a response with info and resource details.
Response Dispatch: Sends response back to client.
Error Handling: If errors occur, generate an error response and send it.
Endpoint: /data/_generate
Method: POST
RequestInfo: Object containing request information.
Query Parameters:
type: Type of the resource for which data needs to be generated.
tenantId: Tenant identifier.
hierarchyType: Type of hierarchy.
forceUpdate: (Optional) Boolean indicating whether to force update existing data.
ResponseInfo: Object containing response information.
GeneratedResource: Array containing the details object of the generated resource.
Client Request: The client sends a POST request to /v1/data/_generate.
Request Validation: Aftern receiving the request, the server validates the request structure and parameters.
Generate Data Process:
Validation: The server validates the generated request.
Data Processing:
Fetch Data: Fetches existing data from the database.
Modify Data: Modify the retrieved data as necessary.
Generate New ID: Generates a new random ID and sets the file store ID to null.
Expire Old Data: Marks existing data status as expired.
Generate New Data: Generates new data based on the request parameters.
Update and Persist: Updates and persists the generated request along with the new data.
Force Update Logic:
If the forceUpdate parameter is set to true:
Search and Update: Searches for existing data of the specified type and updates the existing data information.
If the forceUpdate parameter is not provided or set to false:
Fetch Existing Data: Retrieves already persisted data from the database of the specified type.
Response Creation: After processing the request, the server creates a response containing the details of the generated resource.
Response Dispatch: The server sends the generated response back to the client.
Error Handling: If errors occur, generate an error response and send it.
Fetch Required Columns from MDMS:
Use callMdmsData to get type schema columns in the correct order.
Define Headers:
MDMS schema required columns are headers and ensures column orders.
Localise Headers:
Use getLocalizedHeaders with localizationMap.
Localise Sheet Name:
Use getLocalizedName with localizationMap and generate a sheet.
To add a new column to the Generated sheet, follow these steps:
Search Schema Details
Locate the type schema from the HCM-ADMIN-CONSOLE.adminSchema schema in the workbench.
Identify Column Type
Determine the column type based on the properties defined in the schema:
stringProperties for string-based columns.
numberProperties for numeric-based columns.
enumProperties for enumerated columns.
Define New Column
Add the new column to the schema under the appropriate properties section:
String Column: Include attributes such as name, type, maxLength, minLength, isUnique, isRequired, description, and orderNumber.
Number Column: Include attributes such as name, type, maximum, minimum, isRequired, description, orderNumber, and errorMessage.
Enum Column: Include attributes such as name, enum, isRequired, description, and orderNumber.
Ensure Column Uniqueness
Ensure that the isUnique property is correctly set for string columns to enforce uniqueness.
Column Visibility (Future Implementation)
Note that hideColumn and freezeColumn features will be implemented in the next version.
This process is sufficient for validating the new column in the generated sheet.
If there's a need to reflect the column in APIs, follow these additional steps:
Update createAndSearch.ts File
Modify the createAndSearch.ts file under the defined type parseLogic object.
Integrate the new column into the appropriate data structures used for API operations.
Example :
sheetColumn: A
sheetColumnName: HCM_ADMIN_CONSOLE_FACILITY_CODE
resultantPath: id
type: string
Mapping: Data from column A (HCM_ADMIN_CONSOLE_FACILITY_CODE) in the sheet will be mapped to id in the API data.
By following these steps, you can successfully add and validate a new column in the generated sheet and ensure its reflection in the associated APIs.
General Rules
Locked Headers: The headers in the templates for each data type (user, facility, target) are locked and cannot be changed.
Sheet Protection: Certain sheets within the templates will have specific locked areas to ensure data integrity.
README Sheet: Each type of template includes a README sheet which is read-only and locked.
Target Template
Editable Columns: You can only modify the 'Target' column. All other columns are locked and cannot be edited.
Facility Template
Adding Rows: You are allowed to add new rows to create new facilities.
Editable Columns: You can modify the "Boundary Code" and 'Usage' columns.
Locked Sheets: The boundary data sheet within the facility template is locked and cannot be modified.
Dropdown Columns: The following columns are dropdowns:
Facility Type
Facility Status
Facility Usage
Facility Usage: Facility usage can be 'Active' or 'Inactive'. Active facilities are used in the campaign and require a boundary code to map.
User Template
Adding Rows: You are allowed to add new rows.
Locked Sheets: The boundary data sheet within the user template is locked and cannot be modified.
Dropdown Columns: The following columns are dropdowns:
Role
Employment Type
Data for Dropdowns
The data for the dropdown columns comes from the mdms (Master Data Management System) under the adminSchema master.
Endpoint: /data/_download
Method: POST
RequestInfo: Object containing request information.
Type: (Optional) Type of the resource being downloaded.
TenantId: Tenant identifier.
HierarchyType: Type of hierarchy.
Id: (Optional) ID of the resource being downloaded.
Filters: (Optional) Additional filters for the download request.
campaignId : campaignId
ResponseInfo: Object containing response information.
ResourceDetails: Array containing the details object of the downloaded resource.
Client Request: The client sends a POST request to download data.
Request Validation: Upon receiving the request, the server validates the request structure and parameters.
Data Download Process:
Validation: Validate the download request.
Fetch Data: Fetch existing data of the specified type from the data host service.
Processing: Process the retrieved data as necessary.
Response Creation: After processing the request, the server creates a response containing the details of the latest resource, ensuring that only one result is fetched.
Response Dispatch: The server sends the generated response back to the client.
Error Handling: If errors occur during the process, an error response is generated and sent.
If the downloaded response is empty or not searched with the provided ID, the system automatically starts regenerating a template of the same type. The generation process is triggered by the backend, not through the UI.
Boundary Bulk Upload Overview:
This documentation outlines the process and components of bulk uploading boundaries for a campaign. It covers the proper format of the Excel sheet, unique code generation, functions for boundary entity creation, boundary relationship creation, localisation, and API details.
The Excel sheet should be formatted as follows:
INDIA
INDIA
KARNATAKA
INDIA
KARNATAKA
BLR
INDIA
KARNATAKA
BLR
KORAMANGALA
INDIA
KARNATAKA
BLR
KORAMANGALA
3RD BLOCK
INDIA
KARNATAKA
BLR
KORAMANGALA
3RD BLOCK
EGOV
INDIA
BIHAR
INDIA
BIHAR
PATNA
Unique codes are auto-generated for each boundary level as follows:
INDIA
ADMIN_IN
KARNATAKA
ADMIN_IN_01_KARNATAKA
BLR
ADMIN_IN_01_01_BLR
KORAMANGALA
ADMIN_IN_01_01_01_KORMANGALA
BIHAR
ADMIN_IN_02_BIHAR
PATNA
ADMIN_IN_02_01_PATNA
If there are two districts (boundaries at the same level) with the same name (for example, BLR) under different parent-level boundary, the names will be updated to BLR, BLR-01, and so on.
Purpose:
Generate auto-generated boundary codes based on boundary list, child-parent mapping, element codes map, count map, and request information.
Parameters:
boundaryList: List of boundary data.
childParentMap: Map of child-parent relationships.
elementCodesMap: Map of boundaries to its corresponding auto generated unique codes.
countMap: Map of counts for each boundaries.
request: HTTP request object.
Returns:
Updated element codes map.
Steps:
Initialise Column Data:
Initialise an array to store column data.
Extract Unique Elements:
Iterate through each row of the boundary list.
Extract unique elements from each column.
Generate Boundary Codes:
Iterate over columns to generate boundary codes.
Check if the element code exists in the element codes map.
If not, generate a new code based on parent-child mapping and sequence.
Store the code of the element in the element codes map.
Default Code Generation:
Generate default code if parent code is not found.
Updated Element Codes Map
Return Updated Boundary Data - Auto-Generated Code Map.
Boundary entities are created chunk-wise, with each chunk consisting of 200 codes.
Purpose:
To create new boundary entities in the system from provided boundary codes.
Steps:
Convert Boundary Map:
Change the boundary map to a list of objects with key and value.
Prepare Request:
Set up the request details and initialise lists for boundaries and existing codes.
Chunk Boundary Codes:
Divide the boundary codes into smaller groups.
Fetch Existing Boundaries:
Check the system for existing boundary codes and collect them.
Identify New Boundaries:
Determine which boundary codes are new and add them to the list of boundaries to create.
Create New Boundaries:
If there are new boundaries, send them to the system in groups and log the results.
Handle Existing Boundaries:
Log a message if all boundaries already exist.
Error Handling:
Manage any errors that occur and provide a relevant error message.
Create Boundary Relationship Purpose:
To create boundary relationships in the system from provided boundary codes and their parent-child mappings.
Steps:
Convert Boundary Map:
Transform the boundary map to a list of {key, value} objects.
Initialise Request:
Prepare the request details and activity messages array.
Fetch Existing Relationships:
Retrieve existing boundary relationships and extract their codes.
Identify and Create Relationships:
For each boundary code, check if it exists. If not:
Prepare the boundary relationship data.
Confirm the parent boundary creation.
Create the boundary relationship.
Handle Existing Relationships:
If all relationships already exist, log a validation error.
Attach Activity Messages:
Add activity messages to the request body.
Error Handling:
Catch, log, and handle errors appropriately.
Boundary codes are localised to their corresponding names as specified in the uploaded Excel sheet.
To add more boundaries after the initial upload, use an Excel sheet that includes existing boundary codes. New boundaries without codes will be created in the same way as the first upload.
API request for boundary bulk upload:
Note: Ensure the API endpoint, headers, and payload are customised as per your environment and requirements.
Overview:
In the Campaign Details section, there are 4 screens:
Campaign Type
Campaign Name
Campaign Dates
Campaign Details Summary
This is the first screen when the user clicks on "set-up campaign". In this screen, the user can select the campaign type, and the beneficiary will be prepopulated from the MDMS. This field is mandatory to set up a campaign.
Here, the dropdown will show the list of campaign types in the MDMS. We will fetch the MDMS data from, for more information you can check on configurations from the link here
This screen comes after the campaign type. This step is crucial for saving your campaign as a draft, as the name serves as a unique identifier. After clicking on 'Next', the name will be saved and the user can check from the draft.
This screen asks a user to fill in the start and end dates of the campaign.
This screen will show the summary of the campaign details screen
project-factory/v1/project-type/create
CAMPAIGN_MANAGER
project-factory/v1/project-type/search
CAMPAIGN_MANAGER
/project-factory/v1/project-type/search
CAMPAIGN_MANAGER
/project-factory/v1/project-type/update
CAMPAIGN_MANAGER
In this step, the user will encounter 2 screens:
Boundary Details
Boundary Details Summary
This screen allows users to select the boundaries according to their requirements.
The working of this screen is as follows:
We will fetch the boundary data according to the hierarchy saved in the MDMS.
The file where data is fetched - https://github.com/egovernments/DIGIT-Frontend/blob/console/health/micro-ui/web/micro-ui-internals/packages/modules/campaign-manager/src/Module.js
The hierarchy structure and the lowest boundary will be fetched from the MDMS
For more information on the master data can be referred here
This screen will be shown using the component
Which internally calls the - Selecting boundary component
Validation: The user must select boundaries till the lowest level. If the parent boundary is selected, then the user should select at least one of its child.
This screen displays all the boundaries selected in the previous step.
Boundary localisation for this screen happens by using the combination of hierarchy type and boundary type
It should be in this format.
boundary-service/boundary-relationships/_search
CAMPAIGN_MANAGER
/boundary-service/boundary-hierarchy-definition/_search
CAMPAIGN_MANAGER
In the 'Delivery Details' step, users encounter 3 screens:
Cycles & Deliveries
Delivery Screen
Summary
On this screen, users specify the number of cycles and deliveries. The number of cycles must be at least 1 and can be up to 5. Once the user has defined the number of cycles and deliveries, they can proceed to enter the start and end dates for each cycle.
The number of cycles and deliveries are configurable based on project type. We can configure it in MDMS:
Link:
If data is configured, a user will see the number of cycles and deliveries as per the configuration. A user, however, can increase or decrease if they find it necessary.
The validations added for the start date and the end date of the cycles should not overlap to each other.
After filling in all the cycle details, a user can click on 'Next' and move to the delivery rules screen. Clicking on 'Next' enables a user to store the cycle data in the local storage.
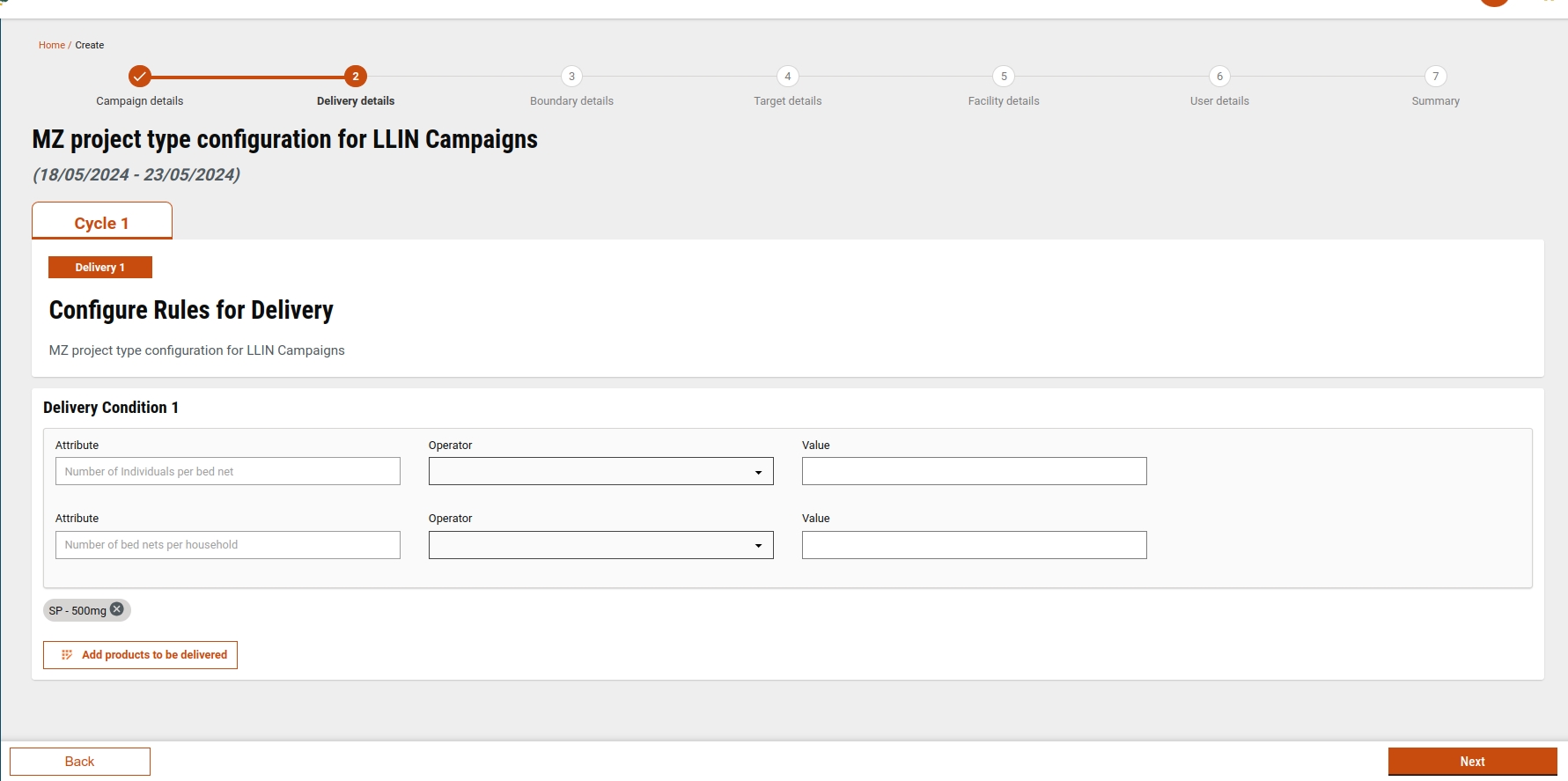
On this screen, users fill in all the delivery details (adding delivery rules, adding conditions in delivery rules, adding products in the delivery rules) of each cycle and delivery that the user has selected in the cycle details screen.
The delivery screen can also be configured based on project type. A user can configure the number of delivery conditions, their attributes, and products. If the data is configured correctly, a user can see the data preloaded in delivery rules and the user can change, remove, or add, if they find it necessary.
A user can add delivery rules up to 5. A user can add conditions in each delivery rule with attribute options having height, weight, gender, and age. For Project type, LLIN-mz configuration is passed in delivery rules in which two fixed attributes are present for the bednet campaign.
After filling in all the delivery rules details, when a user clicks on next, the data will be stored in the localStorage as well as in the draft API. The delivery rules data will be validated in the preview screen.
Reference files:
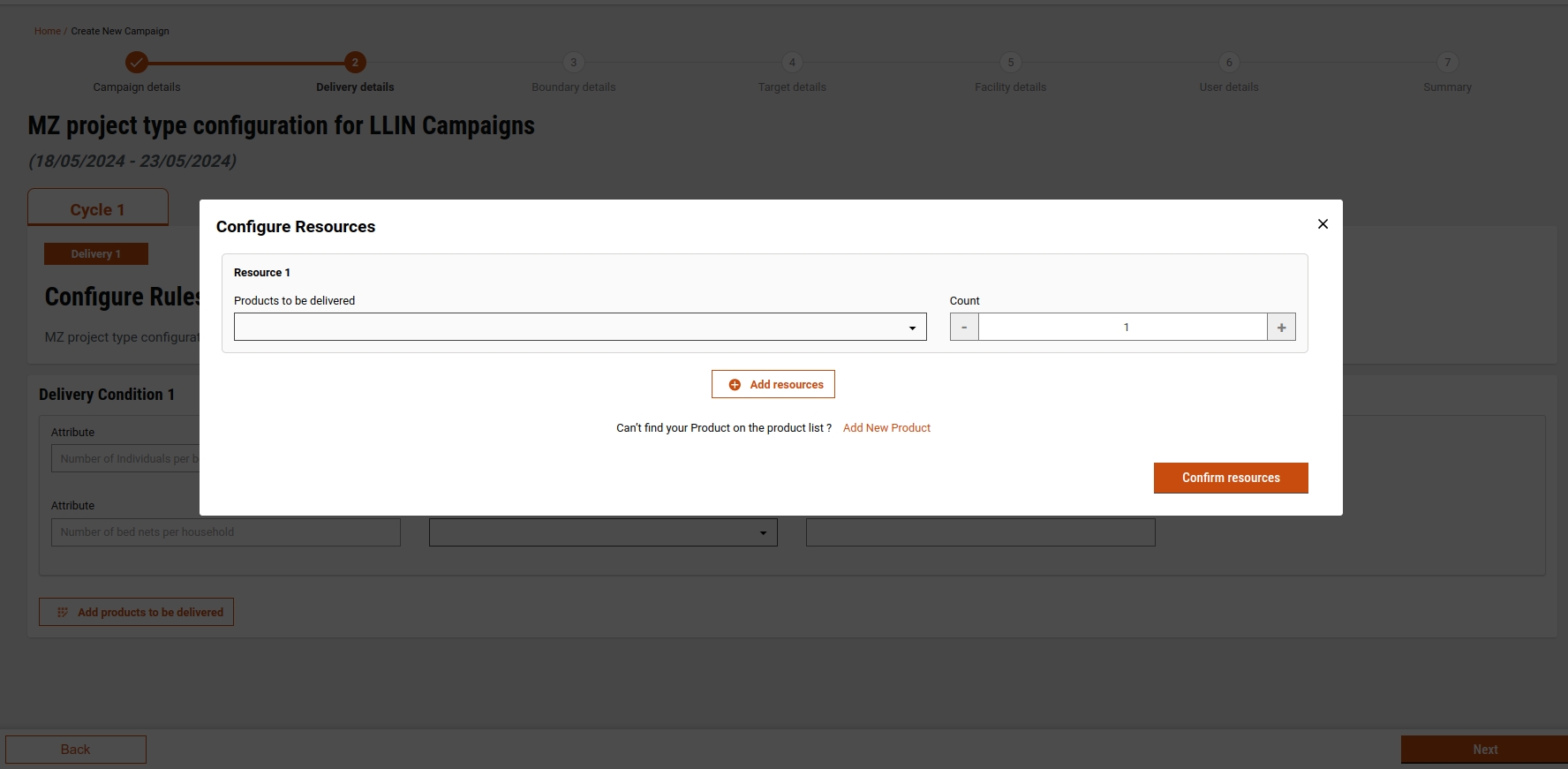
If you click on configure resources on the delivery screen, a pop-up appears where a user can either select or create a product:
Product Screen: When a user clicks on "Add Products to be Delivered", a pop-up screen will appear with a list of product variants where a user can add the products and the number of counts in the delivery rules.
A user can add multiple products to the product screen after clicking on "add more resources" When the user clicks on confirm resources, products will be added to the delivery rules. The user can remove the products as well.
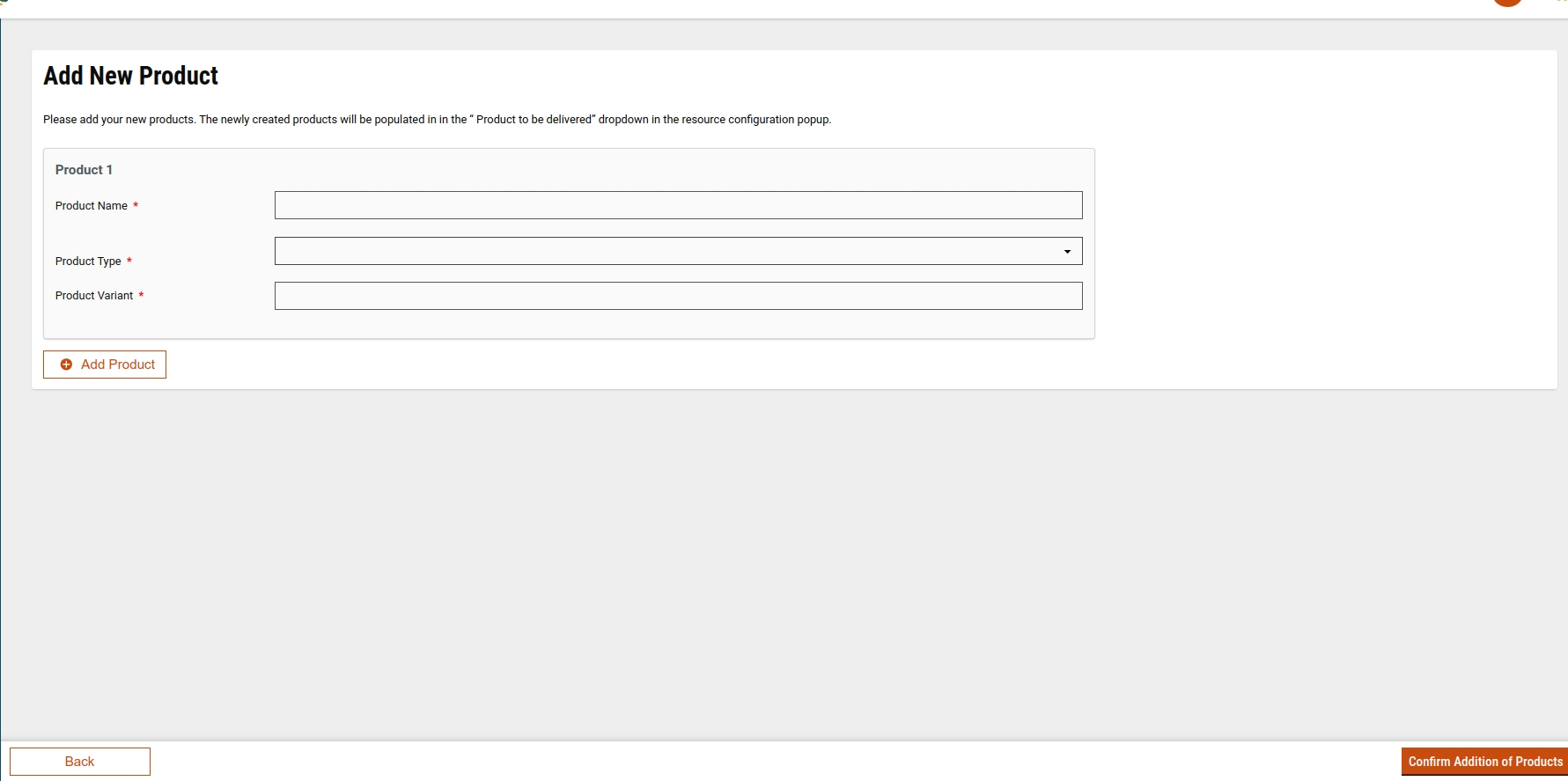
If the product is not present, a user can click on "Add New Product" to create a new product and variant, and subsequently add delivery rules. Clicking on "Add New Product" will open the Create Product screen.
Users can enter product names, product variants, and product types which are sourced from MDMS data. Additionally, a user can create multiple products using the "Add Products" button. After clicking on 'Confirm,' the product will be created, followed by the creation of product variants.
After successful creation, users will be directed to a success response screen.
This screen will show the values the user has added in the cycle configuration screen and delivery screen.
This MDMS schema is used to fetch the details for every product type, to convert the data to the required format used by the screen, we are writing the util.
The following is the structure for the delivery configuration:
projectType: This will be the type of the project. If the selected project type is present in the MDMS, then we use that config.
attrAddDisable: if this is true, we are restricting a user that they cannot add any attribute.
deliveryAddDisable: if this is true, a user cannot add any further delivery rule conditions.
cycleConfig: This will be an object containing cycles and deliveries. This refers to the number of cycles and deliveries that will be shown on the cycle screen.
deliveryConfig: This will be an array of objects, each object representing one delivery condition.
Adding product config is a careful job, adding the wrong product in the config will cause issues while creating a product.
In Value, the product variant ID should be added in the value which will be getting in the below API:product/variant/v1/_search
The name will consist of the name of the product and the variant of the product separated with "-"
for name: product/v1/_search
for variant: product/variant/v1/_search
FilePath:
MDMS:
HOOKS:
We have added the Delivery type at each delivery condition showing the delivery type of the campaign.
It is configurable in mdms for the SMC project type. We can add a default delivery type for each condition.
deliveryConfig: It will contain the default data of all deliveries.
conditionConfig: It will contain default data of each delivery condition of each delivery.
deliveryType: Default value of delivery type.
For IRS to be displayed as the campaign type , initially it needs to added in the MDMS. Master name: projectTypes Module name: "HCM-PROJECT-TYPES"
Changes in delivery details:
The delivery configuration in the MDMS needs to be updated. The desired properties will show the attributes, operator, and value.
For the IRS campaign type, the number of cycles and the number of deliveries will not be editable.
To make the cycle and deliveries not editable, we need to pass one flag in the delivery configuration.
The delivery conditions page will be shown like this in which values will come from the MDMS.
Master name: HOUSE_STRUCTURE_TYPES
Module name: HCM
For the target templates to be generated dynamically, data needs to be added in the adminSchema.
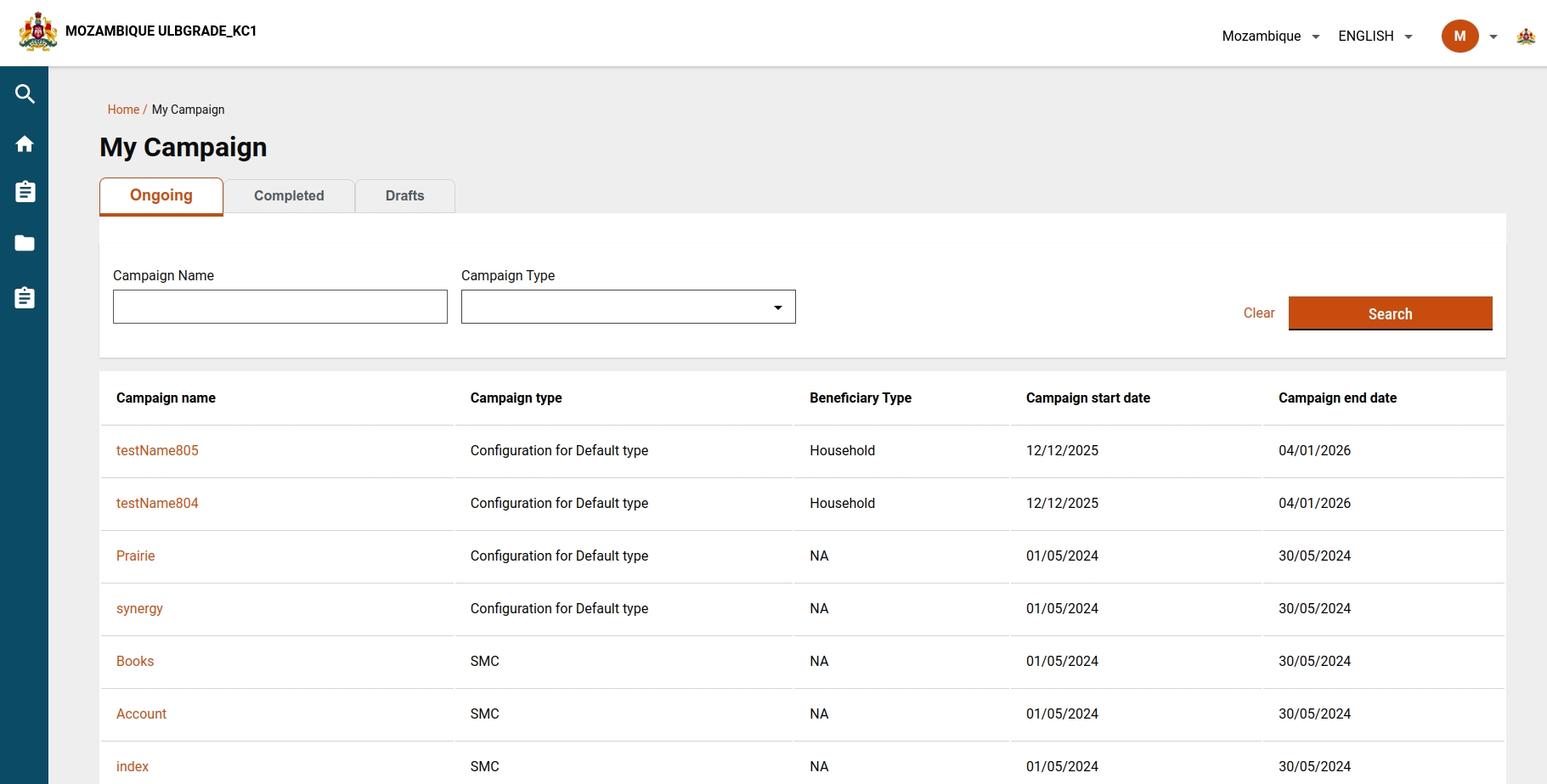
My campaign screen allows users to see the list of campaigns that are in Ongoing, Completed, or Draft status. Users can search campaign by using the campaign name or campaign type. Users can also see a summary of the campaign and complete the campaign creation if it is draft status.
The list of statuses showing in the "My Campaign" screen are:
Ongoing
Completed
Drafts
Failed
Upcoming
After clicking on the My Campaign link from the HCM Campaign module card, the user lands on the My Campaign screen where the user can see all the lists of campaigns of each action in the tab.
On my campaign screen, we are sending the payload:
Campaigns with an end date that has passed the current date are marked as 'Completed'.
Campaigns with a status of 'Started' and no end date, or with an end date in the future, are labeled as 'Ongoing'."
The logic is written in UICustomizations.js
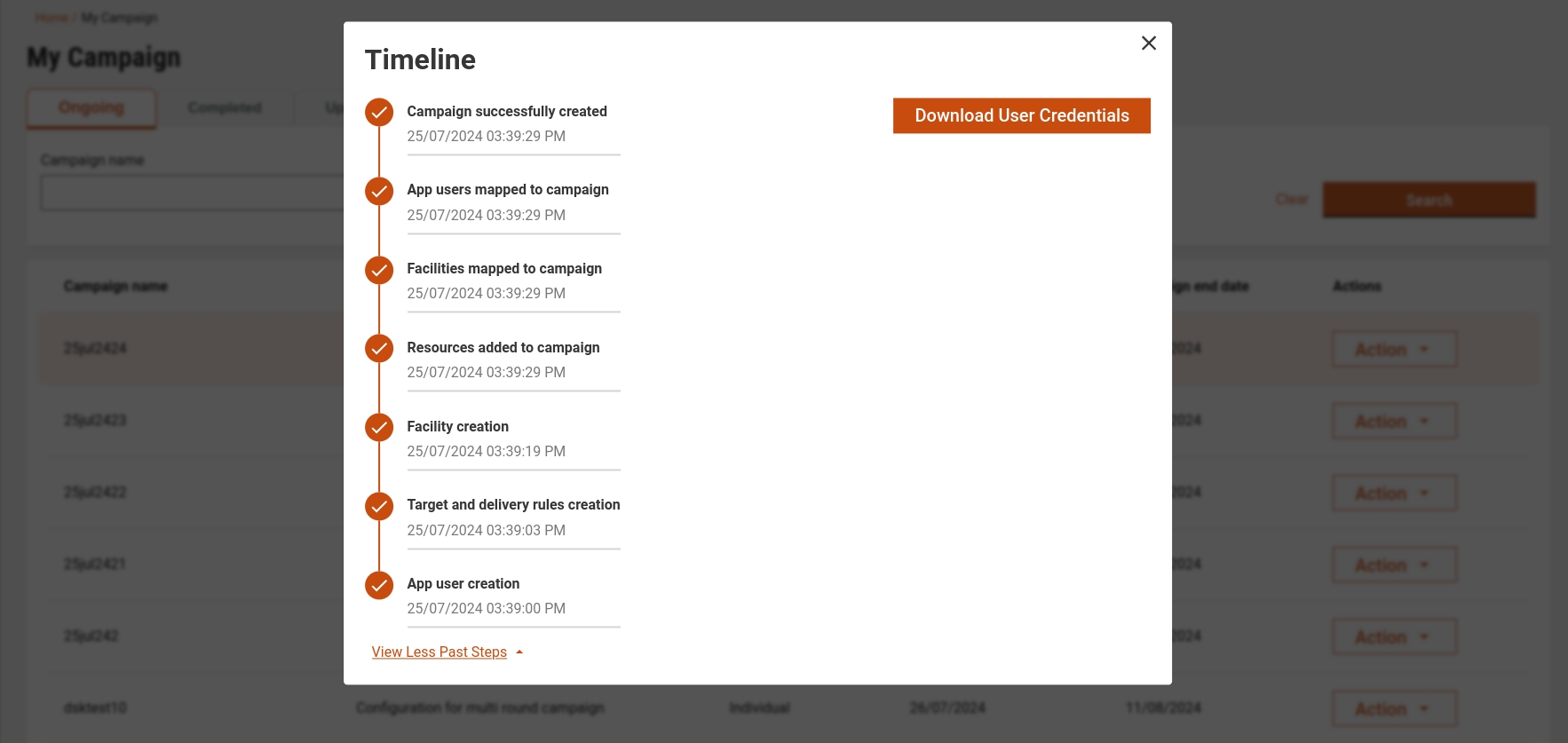
Clicking on campaigns other than draft status will redirect to the summary page of the campaign where the user can see the complete details of the respective campaign.
For the ongoing campaign filtering functionality, we are utilizing the campaignsIncludeDates parameter set to true. The startDate and endDate parameters are both set to the current date. This configuration ensures that the API will return any campaign where the specified startDate or endDate falls within the campaign's defined start and end dates. Additionally, the campaign status is filtered to include campaigns with statuses of created or creating.
campaignsIncludeDates: This boolean parameter is set to true to enable date range filtering.
startDate: The start date for the filter, is set to today's date.
endDate: The end date for the filter, is also set to today's date.
status: The campaign status filter, including the statuses created and creating.
To filter the ongoing campaigns based on the criteria mentioned above, ensure that your request payload includes the following parameters:
campaignsIncludeDates = true: This activates the date range filtering feature.
startDate and endDate = today: By setting both the start and end dates to today's date, the filter will capture any campaigns that are active today.
status = ["created", "creating"]: Filters the campaigns to only include those that are currently in the created or creating status.
For filtering completed campaigns, we use a similar approach with a slight modification to the date parameters and status. Specifically, we will set the endDate parameter to yesterday's date. This configuration ensures that the API returns campaigns that have ended as of yesterday. The statuses to filter will remain creating and created.
endDate: The end date for the filter, is set to yesterday's date.
status: The campaign status filter, including the statuses creating and created.
To filter the ongoing campaigns based on the criteria mentioned above, ensure that your request payload includes the following parameters:
endDate = yesterday: By setting the end date to yesterday's date, the filter will capture any campaigns that have ended by the end of the previous day.
status = ["created", "creating"]: Filters the campaigns to include only those that were in the created or creating status when they ended.
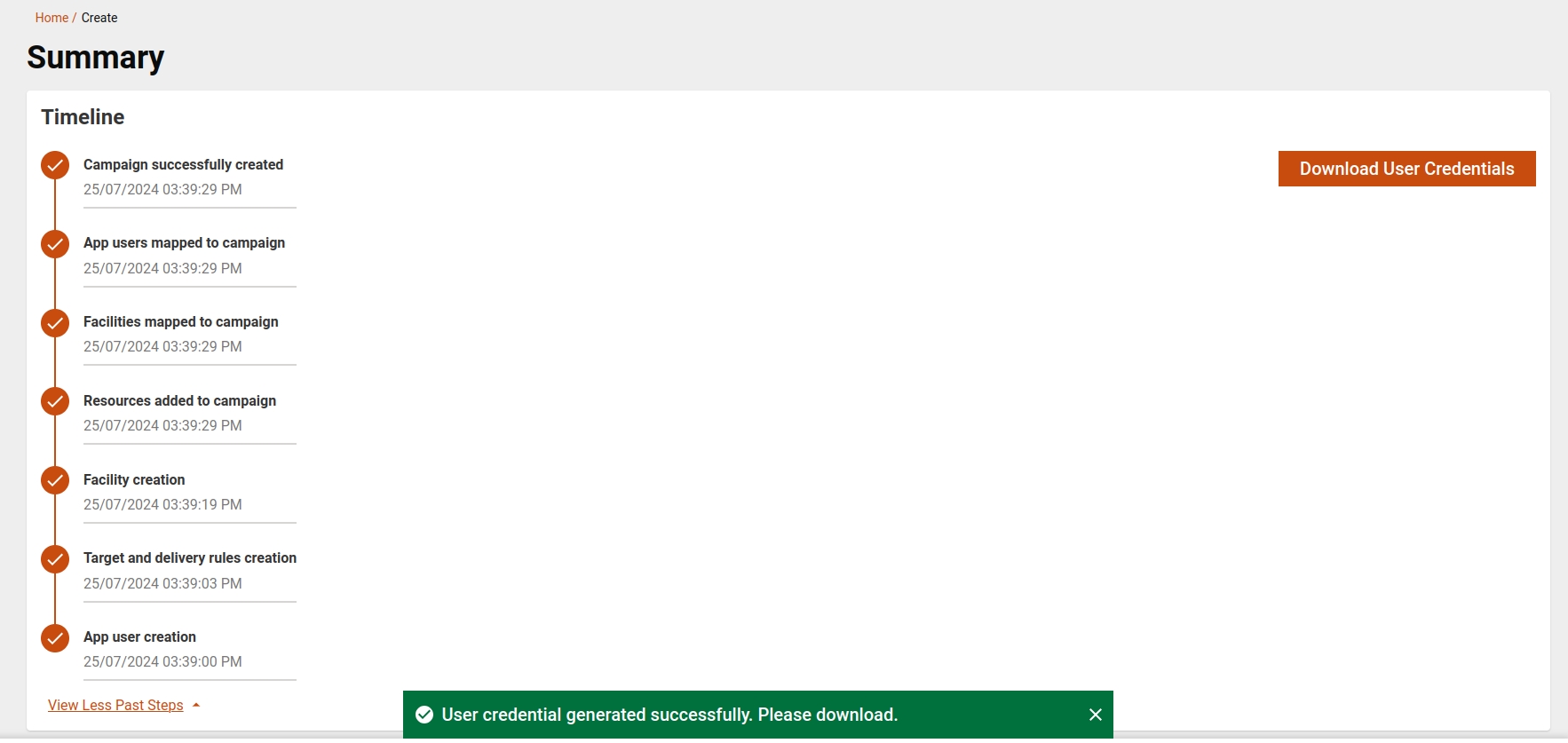
When a user clicks on the completed campaign, they will be redirected to the summary page displaying the campaign details. The success toast message will appear If the user credential sheet is generated successfully. Users can view or download the sheet from the user credential card or download button which appears at the top.
For filtering upcoming campaigns, we use a different approach by setting the campaignsIncludeDates parameter to false and specifying the startDate parameter to tomorrow's date in epoch format. This configuration ensures that the API returns campaigns scheduled to start tomorrow. The statuses to filter will remain creating and created.
campaignsIncludeDates: This boolean parameter is set to false as we are not filtering based on a date range but rather a specific start date.
startDate: The start date for the filter, is set to tomorrow's date in epoch format.
status: The campaign status filter, including the statuses creating and created.
To filter the upcoming campaigns based on the criteria mentioned above, ensure that your request payload includes the following parameters:
campaignsIncludeDates = false: This deactivates the date range filtering feature, focusing the filter on a specific start date.
startDate = tomorrow (epoch date): By setting the start date to tomorrow's date in epoch format, the filter will capture any campaigns scheduled to start tomorrow.
status = ["created", "creating"]: Filters the campaigns to include only those that are in the created or creating status and scheduled to start tomorrow.
When a user clicks on an upcoming campaign, they will be redirected to the summary page displaying the campaign details.
For the drafts campaign, we are passing the status as drafted. It will return all the drafts that are in drafted status
For failed campaigns, we are passing the status as failed. It will return all the drafts that are in failed status
When a user clicks on a failed campaign, they will be redirected to the summary page displaying the campaign details. Additionally, a toast message will appear, showing the error that caused the campaign to fail.
The logic for the step-by-step screens, stepper functionality, storing data in localStorage, creating/updating campaigns, and restructuring API data back into localStorage is all managed within SetupCampaign.js.
All screens are present in the given configuration. Link:
In the configuration:
stepCount represents the step number. Multiple configuration objects can share the same stepCount.
skipAPICall: If this is set to true, the API call for the screen is skipped.
sessionData: Local storage data is passed in custom props, allowing for custom logic to be added to the screens as needed.
In setup campaign, we have functions to perform specific logic:
loopAndReturn: This function takes the delivery rule conditions coming from API response and restructure the data in local storage format.
cycleDataRemap: This function takes the delivery rules data coming from API response and return array of object of start date and end date based on cycles.
reverseDeliveryRemap: This function takes the deliveryConditions from the API response and return the structure of delivery data.
groupByTypeRemap: This function creates the local structure of boundaries.
updateUrlParams: This function is used to update the URL.
In a new campaign, we update the total form when a user clicks on next after entering the data.
After updating the total form data, we store the data in localStorage.
We also call the API to draft the data in case a user wants to come back and resume the campaign.
Refer to the following link:
When a user clicks on the draft campaign, he/she can fetch campaign data from the response.
After getting a response, one can restructure the data in screen format and store it in the local storage.
After updating, the user is redirected to the last screen where additional details are stored in response.
Refer to the following link:
Based on screens, a user can filter the configuration and show the stepper based on the configuration.
Refer to the following link:
As part of v0.3, we have introduced a new vertical stepper and summary screens for all the steps.
The vertical steppers are clickable and the user can navigate between the screens using the steppers.
Summary screens will show all the details entered by the user in that step.
The resource upload details consists of 3 types of uploads:
Upload Target Data
Facility Upload
User Upload
Upload Summary
This screen will come after a user selects the boundaries.
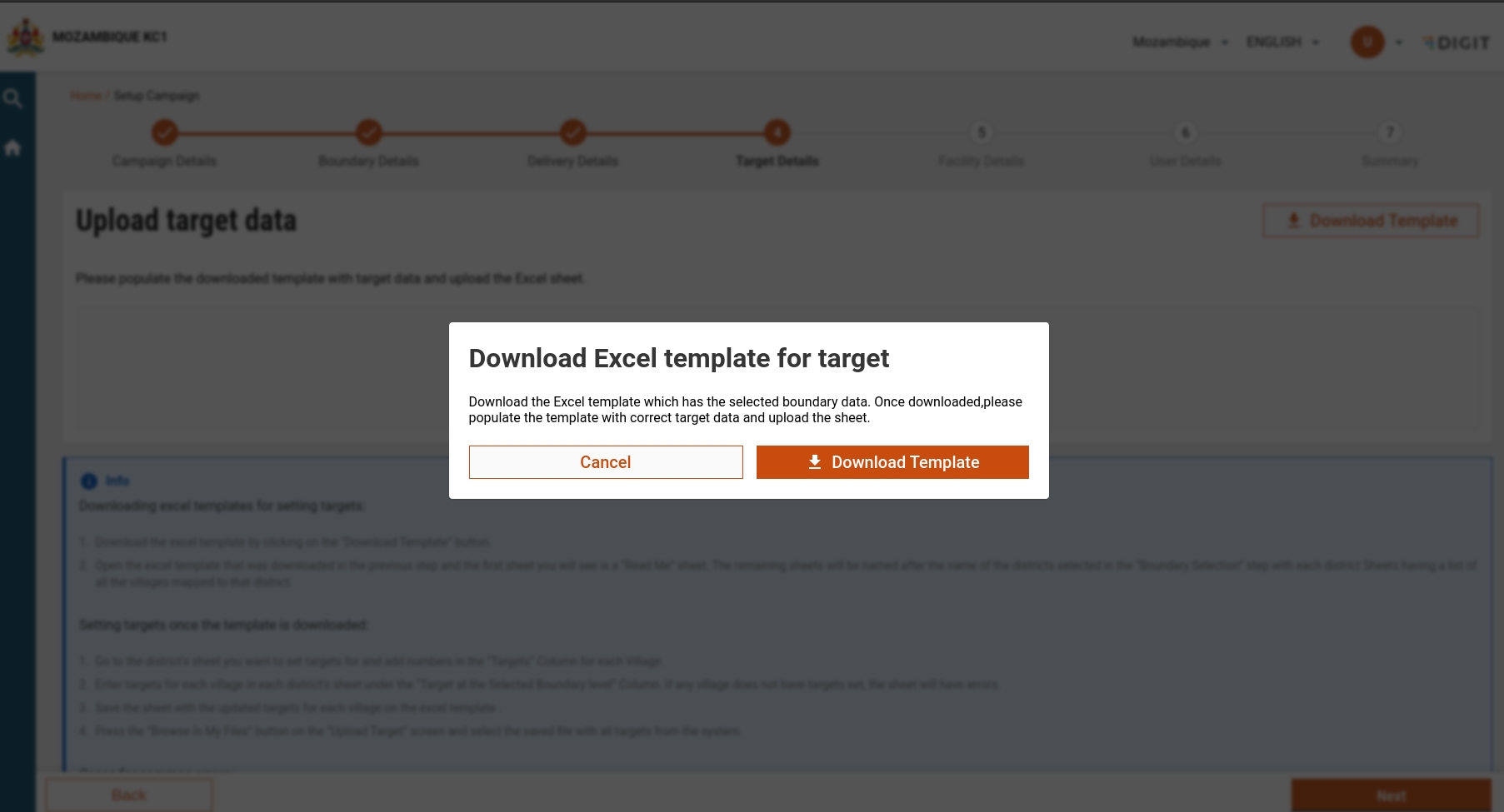
When a user clicks on the download template button, an Excel will get downloaded which will contain readMe, Boundary Data sheet along with the sheets with districts, where the user has to fill the target at the lowest level. After the file is uploaded, it will go for validation. Once validated, a user can go to the next page, where the user can delete the file and move to the next page to upload facility date.
This screen will come after the target upload screen.
In this screen, when a user clicks on the download template, an Excel gets downloaded containing readMe, Facility sheet, and BoundaryData sheet. A user has to fill in the boundary codes and from that sheet, the user has to fill in the facility sheet.
This screen will appear after the facility details screen.
When a user clicks on the download template, an Excel file gets downloaded that consists of readMe, User Sheet, and BoundaryData. The user has to fillout the user sheet only.
This hook will return the ID which is stored in the local storage according to the type:
Next, /project-factory/v1/data/_download is used to download the template.
This screen displays all the files which were uploaded in the previous screens, Validation in this screen -
All the 3 files are mandatory to upload in this step otherwise the user is not allowed to move to the next step.
Schema Module = adminSchema Below is the admin schema-
By using AJV Validation , we are validating the headers of the facility sheet. We are also doing some basic validations for the data such as-
Facility Type can only be Warehouse/Health Facility
Facility Name can only be string
Facility Status can only be Temporary or Permanent etc.
Apart from this, we are also validating sheet names in all the 3 uploads.
For target validation, we use schema only for validating the header of the target and boundary codes. Here, we also validate the target at the lowest level, where the value should be between:
Before calling we are using base time out which is fetched from the MDMS
For more information on this schema, you can refer to:
The screens are using the given below components for upload and validation-
A new pop-up has been added which displays the option to download the template in all three upload screens.
Use Case:
when the user comes after clicking next on the delivery screen and the file is not uploaded then this pop-up is displayed.
File Path:
File Path:
Delivery rule's screen file path:
API call file path:
you can find the config of delivery based on project type and the same acts as the default template.
File Path:
Attribute:
Operator:
Product Type:
File Path:
File path:
File Path:
Path:
All the 3 downloads are happening through the Generate and Download APIs. For the Generate API, the following hook is used:
After uploading the templates, UI validation is done through schema stored in the MDMS: Schema Data link:
For the backend validation, we use the following hook:
Bulk upload:
Preview component:
File screen:
product/variant/v1/_search
CAMPAIGN_MANAGER
product/v1/_search
CAMPAIGN_MANAGER
product/v1/_create
CAMPAIGN_MANAGER
product/variant/v1/_create
CAMPAIGN_MANAGER
project-factory/v1/project-type/update
CAMPAIGN_MANAGER
project-factory/v1/project-type/fetch-from-microplan
MICROPLAN_CAMPAIGN_INTEGRATOR
project-factory/v1/project-type/search
CAMPAIGN_MANAGER
project-factory/v1/project-type/create
CAMPAIGN_MANAGER
project-factory/v1/project-type/update
CAMPAIGN_MANAGER
project-factory/v1/data/_download
CAMPAIGN_MANAGER
/project-factory/v1/project-type/search
{ "RequestInfo": { }, "CampaignDetails": { "tenantId": "mz", "status": [ "failed" ], "createdBy": "ff98f9f6-192b-4e12-8e90-7b73dcd0ad4d", "pagination": { "sortBy": "createdTime", "sortOrder": "desc", "limit": 10, "offset": 0 } } }
/project-factory/v1/data/_download
CAMPAIGN_MANAGER
Params will be different for different types- 1) boundary tenantId:mz
type:boundary
hierarchyType:ADMIN
id:987eadc3-55a0-4553-925d-bf8087f57e5a 2) facilityWithBoundary tenantId:mz
type:facilityWithBoundary
hierarchyType:ADMIN
id:052f59fc-18a7-4e07-816a-f5d8062b56b5 3) userWithBoundary tenantId:mz
type:userWithBoundary
hierarchyType:ADMIN
id:fbfbd393-d053-4f51-9e12-1068b97da292
/project-factory/v1/data/_create
CAMPAIGN_MANAGER
1) type: boundaryWithTarget { "type": "boundaryWithTarget", ""action": "validate",
"campaignId": "13175791-db53-4d10-be90-2dba1c138756" }
2) type: facility { "type": "facility",
"action": "validate",
"campaignId": "13175791-db53-4d10-be90-2dba1c138756"}
3) type: user { "type": "user",
"action": "validate",
"campaignId": "13175791-db53-4d10-be90-2dba1c138756" }
Following is the procedure to configure default templates for checklists for different roles and types of checklist.
Following is the curl to create a template for:
The user needs to create a template for all the combinations of roles, campaign types, and checklist types for which he/she wants to have a checklist configured.
If any option needs to have sub-questions, then add an optionDependency attribute as true in the option's object. All the questions, whether at the parent or children level, need to be different objects and connected via their parentId which is nothing but the parent option's ID.
The question object is represented as a JSON structure with the following key properties:
id (String, Required)
A unique identifier for the question.
Example: "2d4a7b1e-1f2f-4a8a-9672-43396c6c9a1c"
key (Integer, Required)
The question's sequence or order in the questionnaire.
Example: 1
type (Object, Required)
Represents the type of the question.
Contains a code field to specify the question type.
Example: { "code": "SingleValueList" }
level (Integer, Required)
Indicates the hierarchy level of the question.
Example: 1 (Top-level question)
title (String, Required)
The text or content of the question.
Example: "Is there a feedback system for health facilities to report any issues or requests related to bednet distribution?"
value (String/Null, Optional)
Holds the selected value once a choice is made.
Initially null.
options (Array of Objects, Required)
A list of predefined choices for the question.
Each option includes:
id: Unique identifier for the option.
key: Sequence/order of the option.
label: Text describing the option.
optionComment: (Boolean) Indicates if a comment is allowed for the option.
optionDependency: (Boolean) Indicates if selecting the option triggers a dependent question.
parentQuestionId: Links the option to its parent question.
Example:
isActive (Boolean, Optional)
Indicates whether the question is active or visible in the form.
Example: true
parentId (String/Null, Optional)
Specifies the parent question ID if the question is a subquestion.
Example: null for top-level questions.
isRequired (Boolean, Optional)
Indicates if answering the question is mandatory.
Example: false
The question object is represented as a JSON structure with the following key properties:
id (String, Required)
A unique identifier for the question.
Example: "23ca54be-038e-42df-a557-bb5fcd374dd5"
key (Integer, Required)
The question's sequence or order in the questionnaire.
Example: 3
type (Object, Required)
Represents the type of the question.
Contains a code field to specify the question type.
Example: { "code": "MultiValueList" }
level (Integer, Required)
Indicates the hierarchy level of the question.
Example: 1 (Top-level question)
title (String, Required)
The text or content of the question.
Example: "What services or products do you distribute to health facilities?"
value (Array/Null, Optional)
Holds the selected values once options are chosen.
Initially null.
options (Array of Objects, Required)
A list of predefined choices for the question.
Each option includes:
id: Unique identifier for the option.
key: Sequence/order of the option.
label: Text describing the option.
optionComment: (Boolean) Indicates if a comment is allowed for the option.
optionDependency: (Boolean) Indicates if selecting the option triggers a dependent question.
parentQuestionId: Links the option to its parent question.
Example:
isActive (Boolean, Optional)
Indicates whether the question is active or visible in the form.
Example: true
parentId (String/Null, Optional)
Specifies the parent question ID if the question is a subquestion.
Example: null for top-level questions.
isRequired (Boolean, Optional)
Indicates if answering the question is mandatory.
Example: false
The parent question object (SingleValueList) has the following properties:
id (String, Required)
A unique identifier for the question.
Example: "4add5323-fc98-4e71-a783-27dbb922c99f"
key (Integer, Required)
The order or sequence of the question.
Example: 2
type (Object, Required)
Indicates the question type.
Example: { "code": "SingleValueList" }
level (Integer, Required)
Denotes the hierarchy level. For parent questions, this is 1.
Example: 1
title (String, Required)
The content of the question.
Example: "What types of health facilities do you distribute to?"
value (String/Null, Optional)
Holds the selected value after a user chooses an option.
Initially null.
options (Array of Objects, Required)
A list of predefined choices, where:
optionDependency: Determines if selecting the option triggers a nested question.
Example:
isActive (Boolean, Optional)
Specifies whether the question is active.
Example: true
parentId (String/Null, Optional)
null for top-level (parent) questions.
isRequired (Boolean, Optional)
Indicates if the question is mandatory.
Example: false
Structure of Nested Question
The nested question object is similar to the parent question but includes additional context linking it to the triggering parent question.
id (String, Required)
Unique identifier for the nested question.
Example: "c65ac34b-7cc0-4993-a8fe-37e854d2b189"
key (Integer, Required)
Sequence/order of the question.
Example: 4
type (Object, Required)
Specifies the type of question.
Example: { "code": "SingleValueList" }
level (Integer, Required)
The hierarchy level. Nested questions have a higher level (e.g., 2).
Example: 2
title (String, Required)
The text of the nested question.
Example: "Do you have enough products for distribution to health facilities?"
value (String/Null, Optional)
Holds the selected value after a user chooses an option.
Initially null.
options (Array of Objects, Required)
The predefined choices for the nested question.
Example:
isActive (Boolean, Optional)
Indicates whether the question is active.
Example: true
parentId (String, Required)
Links the nested question to the triggering parent option.
Example: "23ace43b-e0b5-428f-9d11-12fc5b10b1ac1"
isRequired (Boolean, Optional)
Specifies if the nested question is mandatory.
Example: false


The timeline provides a visual representation of the campaign creation process. It can be accessed from the summary or through the action button on the "My Campaign" screen. The timeline will be shown for ongoing, upcoming, completed, and failed campaigns.
This timeline shows all the stages of the campaign that are successfully created. A user can download the user credentials as soon as the campaign is created successfully.
The above images show all three timeline steps: upcoming, current, and completed.
A user can also access the timeline from the "My Campaign" screen by clicking on the action button present in the search result.
The timeline will be shown as a pop-up from the "My Campaign" screen. Similar to the summary, while the campaign creation is in progress, it will display all the steps such as upcoming, current, and completed. User credentials will be downloaded once the campaign is successfully created.
/project-factory/v1/project-type/getProcessTrack
POST
params: { campaignId: campaignId, },
This page allows user to create new Boundary and edit it
Boundary Management works based on the HierarchySchema
Refer this config section to know more
Currently, the default hierarchy name is taken from "type": "default", while the hierarchy where data can be created or edited is defined by "type": "campaign".
The landing page of Boundary Management Screen has three buttons
If the boundary has yet not created then the edit boundary field will be disabled
And clicking on create will ask to use default boundary and data from GeoPoDe or create a complete new one.
Using data from GeoPoDe will load the default boundary and ask to add levels
Creating complete new data will require addition of all levels manually
After creation the levels cannot be edited.
Following API’s are called after clicking the Create button:
Upsert: /localization/messages/v1/_upsert all the names of level localised in to new module named hcm-boundary-${hierarchyName}
Create: /boundary-service/boundary-hierarchy-definition/_create
Download: /project-factory/v1/data/_download A polling mechanism is introduced here which keeps on calling the above api until the status is “completed”
Create: /project-factory/v1/data/_create Data create api called if it’s a new hierarchy and here also a polling mechanism is installed which calls the api /project-factory/v1/data/_search continuously at a fixed interval until the status is “completed”
It will automatically redirect to the view hierarchy screen after successful creation. If any level matches with the default hierarchy then it will use its data. Complete excel sheet can be uploaded for all levels all together after downloading the template and uploading it. (The image below is just for reference and levels can vary)
After uploading the excel user can go to next page and view data and confirm it.
Submitting next will create the data.
Submitting next will create the data.
Edit boundary tab on first boundary page will also land to view hierarchy page as of now and will allow to add new data. View all Boundary data will show all hierarchies and user can download the hierarchies too.
Following API is called after clicking “Create Boundary”:
Create: /project-factory/v1/data/_create the uploaded data in excel is sent to data create api with polling mechanism applied. The search API /project-factory/v1/data/_search is called repeatedly with frequency depending on the size of data and network latency taken from the mdms data using master name “baseTimeout” from module named HCM-ADMIN-CONSOLEuntil status is “completed”.
API Details
project-factory/v1/data/_create
BOUNDARY_MANAGER
project-factory/v1/data/_search
BOUNDARY_MANAGER
project-factory/v1/data/_download
BOUNDARY_MANAGER
localization/messages/v1/_upsert
BOUNDARY_MANAGER
boundary-service/boundary-hierarchy-definition/_create
BOUNDARY_MANAGER
boundary-service/boundary-hierarchy-definition/_search
BOUNDARY_MANAGER
boundary-service/boundary-relationships/_search
BOUNDARY_MANAGER
This flow allows the user to update campaign boundary, facility, user, and target details once the campaign is created.
Users can go to update campaign flow from the action button present in my campaigns screen.
Updating the campaign is possible only for ongoing and upcoming campaigns.
Screens coming for this update campaign are-
Selecting Boundary
Update Facility details
Update User details
Update Target
Summary
This is the first screen that is displayed to the user when they try to update the campaign from the My Campaigns screen. This screen is already pre-filled with the boundary data which is selected during the campaign creation.
It is impossible to delete the already selected boundaries, user can always add new boundaries if they want to update.
This screen allows the user to update the facility details:
When the user downloads the current facility template, then that template is already filled with the facility details that the user has entered during the time of campaign creation.
In this user can add the new facilities.
This screen allows the user to update the facility details:
When the user downloads the current user template, then that template is already filled with the user details that the user has entered during the time of campaign creation.
In this user can add a new user.
This screen allows the user to update targets:
When the user downloads the current target template then that template is already filled with the target details that the user has entered during the time of campaign creation.
In this user can add the new targets or change the existing ones.
The file path of all the upload screens:
This helps the user to view the summary of all the entered details in the previous screens:
The update campaign flow works similarly to the setup campaign. But the difference is that here we send the parentId in the URL and fetch it from there.
When the user clicks on next after the boundary details screen, the create API is called with parentID in the params and with action = draft. Then for the subsequent steps update API is called. In the summary screen again create API is called again but with action = 'create'. This action updates the campaign.
If no new boundary selected - If the user has not selected any new boundary then, to update the campaign at least one data upload is necessary.
New Boundaries Added - If the user has selected new boundaries then all the 3 data uploads are necessary for the user.
/project-factory/v1/project-type/create
CAMPAIGN_MANAGER
"action": "draft", "action": "create", to update the campaign
/project-factory/v1/project-type/search
CAMPAIGN_MANAGER
only id is required in params
/project-factory/v1/project-type/update
CAMPAIGN_MANAGER
/project-factory/v1/data/_download
CAMPAIGN_MANAGER
Params will be different for different types- 1) boundary tenantId:mz
type:boundary
hierarchyType:ADMIN
id:987eadc3-55a0-4553-925d-bf8087f57e5a 2) facilityWithBoundary tenantId:mz
type:facilityWithBoundary
hierarchyType:ADMIN
id:052f59fc-18a7-4e07-816a-f5d8062b56b5 3) userWithBoundary tenantId:mz
type:userWithBoundary
hierarchyType:ADMIN
id:fbfbd393-d053-4f51-9e12-1068b97da292
A new 'Actions' column has been added to the "My Campaign" screen, allowing users to perform some tasks skillfully.
Users can click on 'Actions' to choose from the available action options in the menu.
We've added config for column actions in myCampaignConfig.js
In UICustomization.js, we have added a component that needs to be rendered for the action column under additionalCustomizations.
We have added an onActionSelect function which acts based on the selected option.
Actions are different according to the different campaign status
Here user will get all the actions such as:
For the case of ongoing campaigns user is able to update the campaign , configure checklist and to view user credentials , all the 4 options will be visible.
For the case of completed campaings user will not be able to update the campaign. Only view the user credentials:
Here user will get all the actions such as: For the case of upcoming campaigns user is able to update the campaign , configure checklist and to view user credentials ,all the 4 options will be visible.
Draft state will have no action button.
Failed state will have no action button.
File Path:
Config:
UICustomisation:
The checklist requires data from mdms which is configurable and have the following schema codes:
Example Data for the above schema codes// Some code```postman_json
User enters the checklist search screen by clicking on the configure app.
The Search Checklist is the screen where u can search for created checklist and also create checklists for whose templates have been created. View button is present for the created checklists and Configure button for those which need to be created.
The Create Checklist page loads the default template for that particular use role and checklist type and then can be edited as per the user. On submission the api creates the checklist (service definition) and create localisation for all the questions and options
The questions can be Single Choice (Radio button) or Multiple Choice (Checkbox) and each single choice option can have multiple sub questions. Nesting is allowed uptil 3 levels. Nesting can be done by clicking on the Dependency button. Options can also have comments attached to them. Add options and delete options feature is also given. The required checkbox is to make any question mandatory.
Preview Checklist shows the mobile view of the created checklist
The View Checklist page shows the current checklist and is non-editable.
The create and update pages work same. The update checklist page loads the already created questions to be edited and can be reached by clicking the update button on view checklist button.
The following API’s are called while checklist creation :
Question type search: /mdms-v2/v2/_search this is used to search the types of questions like radio button or checkboxes and these are taken from the mdms with schema code HCM-ADMIN-CONSOLE.appFieldTypes
Create: /service-request/service/definition/v1/_create : used to create the service definition which is the checklist.
Upsert: /localization/messages/v1/_upsert All the questions and options are localised by this api under the module name hcm-checklist
The following api is called to view the previously created checklist :
service-request/service/definition/v1/_search
The following API’s are called while checklist update :
Create: /service-request/service/definition/v1/_update : used to update the service definition which is already created.
service-request/service/definition/v1/_create
CAMPAIGN_MANAGER
service-request/service/definition/v1/_update
CAMPAIGN_MANAGER
service-request/service/definition/v1/_search
CAMPAIGN_MANAGER
localization/messages/v1/_upsert
CAMPAIGN_MANAGER
This screen enables users to update the start date, end date, and cycle dates for both ongoing and upcoming campaigns. Additionally, an 'Actions' column has been added to the "My Campaign" screen, providing more options for managing the campaigns.
When a user clicks on 'Actions', they will see the "Update Dates" option. Selecting "Update Dates" redirects the user to the update date screen.
We have added an MDMS configuration flag to determine whether the dates can be updated with or without boundaries. Depending on the MDMS flag, the appropriate screen will be rendered.
If the MDMS flag for updating dates with a boundary is set to true, the corresponding screen for updating dates will be rendered.
If the MDMS flag for updating with a boundary is set to true, the corresponding screen will be rendered. On this screen, the user first selects the hierarchy level and boundary they wish to update. After making their selection, the user clicks the 'Confirm' button.
Based on the selected boundaries, the corresponding dates are displayed. The user can then change the dates and cycle dates as needed. Fields with dates that have already passed (relative to today) are made non-editable.
After making the desired changes, the user clicks the 'Confirm' button to update the dates. Once the update is successful, a success response screen is shown, and the user is redirected back to the "My Campaign" screen.
If the MDMS flag is set to false, the corresponding screen is rendered to update the dates without considering boundaries, at the root level.
When the user clicks on "Update Date" for the respective campaign, the update date screen is shown with all the prefilled start and end dates. The user can then make the necessary changes.
The user can change the editable dates. Any date fields that have passed the current date are non-editable. Once the user confirms the date change, the data is updated. After a successful update, the user is redirected to a success screen.
MDMS configuration to check whether the update date is at the root level or boundary level: https://github.com/egovernments/egov-mdms-data/blob/UNIFIED-DEV/data/mz/health/hcm-admin-console/dateWithBoundary.json
MDMS Link:
/health-project/v1/_search?tenantId=mz&limit=10&offset=0
CAMPAIGN_MANAGER
/health-project/v1/_update
CAMPAIGN_MANAGER
/health-project/v1/_search?tenantId=mz&limit=10&offset=0
CAMPAIGN_MANAGER
/health-project/v1/_update
CAMPAIGN_MANAGER
boundary-service/boundary-hierarchy-definition/_search
CAMPAIGN_MANAGER