Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
This section provides technical details about business service setup, configuration, deployment, and API integration.
v2 configuration details
The Collection Service serves as a revenue collection platform for all the billing systems through cash, cheque, demand drafts, or the swipe machine. It enables payment for all services provided by the eGov platform at a single point directly from the citizen or over-the-counter collection within municipalities.
Prior Knowledge of Java/J2EE
Prior Knowledge of SpringBoot
Prior Knowledge of REST APIs and related concepts like path parameters, headers, JSON, etc
Prior Knowledge of Kafka and related concepts like Producer, Consumer, Topic, etc.
The following services must be up and running:
egov-localization
egov-mdms
egov-idgen
egov-url-shortening
billing-service
Allows citizens to create a payment.
Allows employees to create the payment for the citizen indirectly.
Provides facilities to capture partial and advanced payments based on configs.
Allows payment cancellation to help with scenarios of bad checks and other failed payment scenarios.
Integrates with billing service for demand back-update of payment.
deploy the latest version of the collection-services docker builds.
The MDMS data configuration uses the same data updated by the Billing-Service.
Billing Service | Configuration-Details: Refer to the MDMS data configuration here.
The table below lists the application properties.
collection.receipts.search.paginate
true/false
By setting this property true, show you the search result of receipt in a bucket(page) which contains a certain number of records.
is.payment.search.uri.modulename.mandatory=true
TRUE/FALSE
Make module name in URI path mandatory
collection.receipts.search.default.size
Certain number (say 30)
Give the 30 records at a time and next 30 results are in the next page.
collection.is.user.create.enabled
true/false
By setting this property true, enabling the creation of user with receipt creation
receiptnumber.idname
This property is used for creation of receipt number using ID-GEN service
receiptnumber.servicebased
true/false
If servicebased is set to false, use default state level format for the format of receipt number and if it is set to true the format for the receipt number has to be mentioned in MDMS
receiptnumber.state.level.format
[cy:MM]/[fy:yyyy-yy]/[SEQ_COLL_RCPT_NUM]
Default state level format for the receipt number.
collection.payments.search.paginate
true/false
By setting this property true, show you the search result of payment records in a bucket(page) which contains a certain number of records.
egov.collection.payment-create
The kafka topic on which the record has to push/pull when payment is created.
egov.collection.payment-cancel
The kafka topic on which the record has to push/pull when payment is cancelled.
egov.collection.payment-update
The kafka topic on which the record has to push/pull when payment is updated.
Collection service can be integrated with any organization or system that requires a payment system to keep track of its payments. Organizations can customize part of the application or its functionalities based on their requirements.
Easy payments and tracking of payments.
Configurable functionalities according to client requirement
Customers can create a payment using the /payments/_create
Actors on the system can keep track of payments using /payments/_searchendpoint
Once the payment is done and it encounters a technical issue that is beyond the system - the payment can be cancelled with /payments/_workflow
For employees to access the payments API the respective module name should be appended to the payment API path - /payments/PT/_workflow. Here PT refers to the property module.
Billing-Collection-Integration - Refer to the integration details.
Doc Links
Billing-service
Id-Gen service
url-shortening
MDMS
API List
/payments/_create
/payments/_update
/payments/_workflow
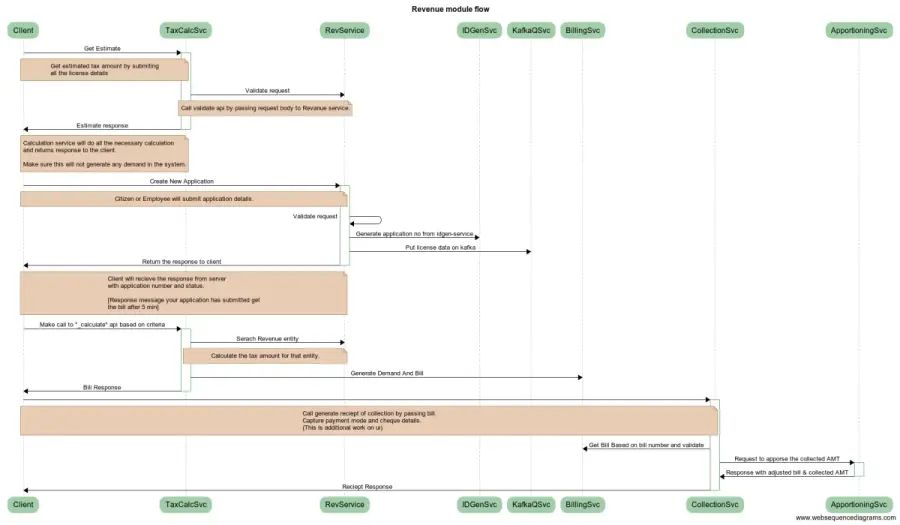
The main objective of the billing module is to generate the bill for all revenue-based business services. To serve the bill, the Billing-Service requires demand. Demands will be prepared by the revenue modules and stored by billing based on which it generates the Bill.
Prior Knowledge of Java/J2EE.
Prior Knowledge of Spring Boot.
Prior Knowledge of KAFKA
Prior Knowledge of REST APIs and related concepts like path parameters, headers, JSON, etc.
Prior knowledge of demand-based systems.
The following services should be up and running:
user
MDMS
Id-Gen
URL-Shortening
notification-sms
eGov billing service creates and maintains demands.
Generates bills based on demands.
Updates the demands from payment when the collection service takes a payment.
Deploy the latest image of the billing service available.
In the MDMS data configuration, the following master data is needed for the functionality of the billing.
MDMS
Business Service JSON
TAX-Head JSON
Tax-Period JSON
bs.businesscode.demand.updateurl
{
Each module’s application calculator should provide its own update URL. if not present then a new bill will be generated without making any changes to the demand.
bs.bill.billnumber.format
BILLNO-{module}-[SEQ_egbs_billnumber{tenantid}]
IdGen format for the bill number
bs.amendment.idbs.bill.billnumber.format
BILLNO-{module}-[SEQ_egbs_billnumber{tenantid}]
is.amendment.workflow.enabled
true/false
enable disable workflow of bill amendment
Billing service can be integrated with any organization or system that wants a demand-based payment system.
Easy to create and simple process of generating bills from demands
The amalgamation of bills period-wise for a single entity like PT or Water connection.
Amendment of bills in case of legal requirements.
Customers can create a demand using the /demand/_create
Organizations or Systems can search the demand using /demand/_searchendpoint
Once the demand is raised the system can call /demand/_update endpoint to update the demand as per need.
Bills can be generated using, which is a self-managing API that generates a new bill only when the old one expires /bill/_fetchbill.
Bills can be searched using /bill/_search.
Amendment facility can be used in case of a legal issue to add values to existing demands using /amendment/_create and /amendment/_update can be used to cancel the created ones or update workflow if configured.
Interaction Diagram V1.1:
Doc Links
Id-Gen service
****
url-shortening
MDMS
API List
/demand/_create, _update, _search
/bill/_fetchbill, _search
/amendment/_create, _update
What is apportioning?
Adjusting the receivable amount with the individual tax head.
Types of apportioning V1.1
Default order-based apportioning(Based on apportioning order adjust the received amount with each tax head).V1.1
Types of apportioning V1.2: (TBD)
Proportionate-based apportioning (Adjust total receivable with all the tax heads equally)
Order & percentage-based apportioning (Adjust total receivable based on order and the percentage which is defined for each tax head).
Principle of apportioning
The basic principle of apportioning holds that if the full amount is paid for any bill then each individual tax head should get nullified with their corresponding adjusted amount.
Example: Case 1: When there are no arrears all tax heads belong to their current purpose.
Example: given below
Pt_tax
1000
6
1000
1000
750
750
AdjustedAmt
1000
-250
-750
-750
RemainingAMTfromPayableAMT
0
0
0
0
Penality
500
5
500
500
AdjustedAmt
500
-500
RemainingAMTfromPayableAMT
1000
250
Interest
500
4
500
500
AdjustedAmt
500
-500
RemainingAMTfromPayableAMT
1500
750
Cess
500
3
500
500
AdjustedAmt
500
-500
RemainingAMTfromPayableAMT
2000
1250
Exm
-250
1
-250
-250
AdjustedAmt
-250
250
RemainingAMTfromPayableAMT
2250
1750
Rebate
-250
2
-250
-250
AdjustedAmt
-250
250
RemainingAMTfromPayableAMT
2500
750
Case 2: Apportioning with two years of arrear: Example: The apportioning details for the financial year 2014-15 are given below.
Pt_tax
1000
2014
2015
6
Current
AdjustedAmt
0
Penality
500
2014
2015
5
Current
AdjustedAmt
0
Interest
500
2014
2015
4
Current
AdjustedAmt
0
Cess
500
2014
2015
3
Current
AdjustedAmt
0
Exm
-250
2014
2015
1
Current
AdjustedAmt
0
The table below illustrates the demand structure generated in case there are no payments for the specified financial year (2015-16).
Pt_tax
1000
2014
2015
6
Arrear
AdjustedAmt
0
Pt_tax
1500
2015
2016
6
Current
AdjustedAmt
0
Penalty
600
2014
2015
5
Arrear
AdjustedAmt
0
Penalty
500
2015
2016
5
Current
AdjustedAmt
0
Interest
500
2014
4
Arrear
AdjustedAmt
0
Cess
500
2014
3
Arrear
AdjustedAmt
0
Exm
-250
2014
1
Arrear
AdjustedAmt
0
The consumer sometimes needs additional amounts (Amendments) added to their bill due to reasons from outside of the system. The addition of amounts happens with respect to the consumer code of the entity in the product(PT, WS, etc..,), any unpaid demand in the system is a candidate for amendments.
Prior knowledge of billing-service in the DIGIT framework.
Amendment mainly works with two types of functionality as follows:
Amendment
Demand
Bill Amendment provides a separate flow that triggers the workflow for validating the process of adding additional amounts to existing demands. This validation was earlier available only to the respective modules. An amendment is allowed only when there is a need to add or reduce the amount from the existing bill belonging to an entity. The reasons for such cases could be:
Court case settlement
One time waiver
Write-offs
DCB correction (old demands in paid status)
Property tax remission
Criteria:
Below are certain prerequisites to creating an amendment,
presence of demand in the billing system
any one of the reasons listed above
valid document proof for the reason
there is no other amendment already in the workflow
Procedure:
The process of adding an amendment in specific scenarios is given below.
There are two scenarios on how an amendment is completed based on the paid status of the existing demands in the system.
1. when demand is unpaid/partially paid
Create a demand (Or an existing demand can be used) with demand detail → DD1.
Do not pay the bill or make a partial payment.
Create an amendment for the same consumer code (with demand detail → DD2).
Approve the amendment - the response should return an amendment with the status CONSUMED.
Search the demand or fetch the bill for the consumer code. The demand/bill should contain demand details of the demand and amendment together with DD1 and DD2 in the same demand/bill.
2. when demand is completely paid
Create demand and make complete payment or choose a consumer code which is fully paid.
Create amendment (with demand detail → DD1).
Approve amendment - the response should be APPROVED.
Create new demand for the consumer code (with demand detail → DD3). The demand response should contain two demand details DD1 and DD2 saved to the demand.
The amendment search returns CONSUMED status after the demand is created.
IMPACT: Does not impact any other functionality other than adding demand details to demands on APPROVAL.
IMPACTED BY: Existence of demands in the system.
Billing Service | Configuration-Details: Refer to billing-service config for MDMS data. The amendment makes use of the same data set.
WORKFLOW CONFIG:
Amendment integration helps organizations add additional value to the demand without any change in the system.
Easy to create and simple process of updating demands
Helps ease changes into the system which are not part of normal functionality - Amendment of bills in case of legal requirements.
This is integrated into the billing system by default.
The amendment facility can be used in case of a legal issue to add values to existing demands using /amendment/_create. The parameter /amendment/_update is used to cancel the created updates or update configured workflows.
{yet to be added}
API Definition
API List
/amendment/_create, _update
````
````
``
__All content on this page by eGov Foundation is licensed under a Creative Commons Attribution 4.0 International License.
"PT":"
All content on this page by eGov Foundation is licensed under a Creative Commons Attribution 4.0 International License.
All content on this page by eGov Foundation is licensed under a Creative Commons Attribution 4.0 International License.
The Collection service is to serve as a revenue collection platform for all the billing systems through cash, cheque, demand draft, and swipe machines. It enables payment for all services provided by the eGov platform at a single point for the citizen and counter collection in municipal alike.
Prior knowledge of Java/J2EE
Prior knowledge of SpringBoot
Prior knowledge of REST APIs and related concepts like path parameters, headers, JSON, etc
Prior knowledge of Kafka and related concepts like Producer, Consumer, Topic, etc.
The following services should be up and running:
egov-localization
egov-mdms
egov-idgen
egov-url-shortening
billing-service
Allows citizens to create a payment.
Allows employees to create the payment for the citizen indirectly.
provides facilities to capture partial and advanced payments based on configs.
allows payment cancellation to help with scenarios of bad checks and other failed payment scenarios.
Integrates with billing service for demand back-update of payment.
deploy the latest version of the collection-services docker builds.
The MDMS data configuration uses the same data updated by Billing-Service
Billing Service | Configuration-Details: Refer to the MDMS data config from here.
Following are the properties in the application.properties
collection.receipts.search.paginate
true/false
By setting this property true, show you the search result of receipt in a bucket(page) which contains a certain number of records.
is.payment.search.uri.modulename.mandatory=true
TRUE/FALSE
Make module name in URI path mandatory
collection.receipts.search.default.size
Certain number (say 30)
Give the 30 records at a time and next 30 results are in the next page.
collection.is.user.create.enabled
true/false
By setting this property true, enabling the creation of user with receipt creation
receiptnumber.idname
This property is used for creation of receipt number using ID-GEN service
receiptnumber.servicebased
true/false
If servicebased is set to false, use default state level format for the format of receipt number and if it is set to true the format for the receipt number has to be mentioned in MDMS
receiptnumber.state.level.format
[cy:MM]/[fy:yyyy-yy]/[SEQ_COLL_RCPT_NUM]
Default state level format for the receipt number.
collection.payments.search.paginate
true/false
By setting this property true, show you the search result of payment records in a bucket(page) which contains a certain number of records.
egov.collection.payment-create
The kafka topic on which the record has to push/pull when payment is created.
egov.collection.payment-cancel
The kafka topic on which the record has to push/pull when payment is cancelled.
egov.collection.payment-update
The kafka topic on which the record has to push/pull when payment is updated.
Collection service can be integrated with any organization or system that wants a payment system to keep track of its payments. Organizations can customize part of the application or its functionality based on their requirements.
Easy payments and tracking of payments.
Configurable functionalities according to client requirements.
Customers can create a payment using the /payments/_create.
Actors on the system can keep track of payments using /payments/_searchendpoint.
Once the payment is done but it encounters a technical issue outside of the system then it can be cancelled with /payments/_workflow.
For employees to access the payments API the respective module name should be appended after the payment API path - /payments/PT/_workflow - here PT refers to the property module.
Port forward the collection service to the current environment where the IFSC CODE bank details data is to be migrated. Sample command - 1kubectl port-forward collection-services-76b775f976-xcbt2 8055:8080 -n egov
Import postman collection from API list which refers as /preexistpayments/_update and runs with the same localhost to where we port forwarded using the above command.
Expected result. In the EGCL_PAYMET table where IFSCODE data is present for those records, EGCL_PAYMET.ADDITIONALDETAILS bankdetails will be updated.
Ex: For IFSCCODE : UCBA0003047 Response from API https://ifsc.razorpay.com/UCBA0003047 is updated in EGCL_PAYMET.ADDITIONALDETAILS as {"bankDetails": {"UPI": true, "BANK": "UCO Bank", "CITY": "BHIKHI", "IFSC": "UCBA0003047", "IMPS": true, "MICR": "151028452", "NEFT": true, "RTGS": true, "STATE": "PUNJAB", "SWIFT": "", "BRANCH": "BHIKHI", "CENTRE": "MANSA", "ADDRESS": "ADJOINING HP PETROL PUMP MANSA ROADDISTRICT MANSA","BANKCODE":"UCBA","DISTRICT":"MANSA","CONTACT":"+918288822548"}
Billing-Collection-Integration Refer to the integration with details and explanation.
Billing-service
Id-Gen service
url-shortening
MDMS
/payments/_create
/payments/_update
/payments/_workflow
/preexistpayments/_update
DSS Backend Configuration Manual
DSS has two sides to it. One is the process in which the data is pooled to ElasticSearch and the other is the way it is fetched, aggregated, computed, transformed and sent across. DSS must be configurable since the entire process involves playing around with a variety of data sets. This ensures easy configuration of data sets in new scenarios.
This document explains the steps on how to define the configurations for both sides of DSS Analytics and Ingest Pipeline Services.
Ingest: Micro Service which runs as a pipeline and manages to validate, transform and enrich the incoming data and pushes the same to ElasticSearch Index
Analytics: Micro Service which is responsible for building, fetching, aggregating and computing the Data on ElasticSearch to a consumable Data Response. Which shall be later used for visualizations and graphical representations.
JOLT: JSON to JSON transformation library written in Java where the "specification" for the transform is itself a JSON document
Modules / Domain Level: These are the Services in this context. Each of the services, such as Property Tax, Trade License, Water and Sewerages are considered as Modules / Domains
Chart: Each individual graphical representation is considered as a Chart in specific. For example, a Metric of Total Collection is considered as a Chart.
Visualization: Group of different Charts is considered as a Visualization. For example, the group of Total Collection, Target Collection and Target Achieved is considered as a Metric Collection of Charts and thus it becomes a Visualization.
Discussed below are the ingest pipeline configuration details -
Topic Context Configurations
Validator Schema
JOLT Transformation Schema
Enrichment Domain Configuration
JOLT Domain Transformation Schema
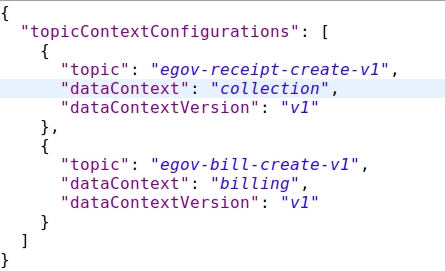
Topic context configuration is an outline to define which data is received on which Kafka Topic.
Indexer Service and many other services are sending out data on different Kafka Topics. If the Ingest Service receives the data and passes it through the pipeline, the context and the version of the data received have to be set. This configuration is used to identify which Kafka topic consumed the data and the mapping details.
Click here for the full configuration
topic
Holds the name of the Kafka Topic on which the data is being received
dataContext
Context Name which needs to be set for further actions in the pipeline
dataContextVersion
Version of the Data Structure is set here as there might be different structured data at a different point in time
Validator schema is a configuration schema library from Everit. By passing the data against this schema, it ensures whether the data abides by the rules and requirements of the schema that has been defined.
Click here for an example configuration
JOLT is a JSON to JSON transformation library. In order to change the structure of the data and transform it in a generic way, JOLT has been used.
While the transformation schemas are written for each data context, the data is transformed against the schema to obtain transformed data.
Follow the slide deck for JOLT Transformations
Click here for an example configuration
This configuration defines and directs the enrichment process that the data goes through.
For example, if the data which is incoming is belonging to a collection module data, then the collection domain config is picked. And based on the specified business type the right config is picked.
In order to enhance the data of collection, the domain index specified in the configuration is queried with the right arguments and the response data is obtained, transformed and set.
Click here for an example configuration
id
Unique Identifier for the Configuration within the configuration document
businessType
This defines as in which kind of Domain / Service is the data related to. Based on this business type, query and enhancements are decided
indexName
Based on Business Type, Index Name is defined as to which index has to be queried to get the enhancements done from
query
Query to execute to get the Domain Level Object is defined here.
targetReferences
sourceReference
Fields which are variables in order to get the domain level objects are defined here. The variables and where all the values has to be picked from are documented here
As a part of enhancement, once the domain level object is obtained, we might not need the complete document as is in the end data product.
Only those parameters which should be or can be used for aggregation and representation are to be held and others are to be discarded.
In order to do that, we make use of JOLT again and write schemas to keep the required ones and discard the unwanted ones.
The above configuration is used to transform the data response in the enrichment layer.
Click here for an example configuration
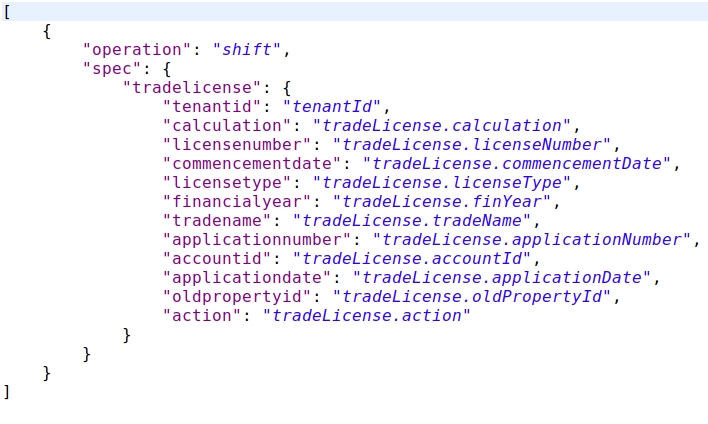
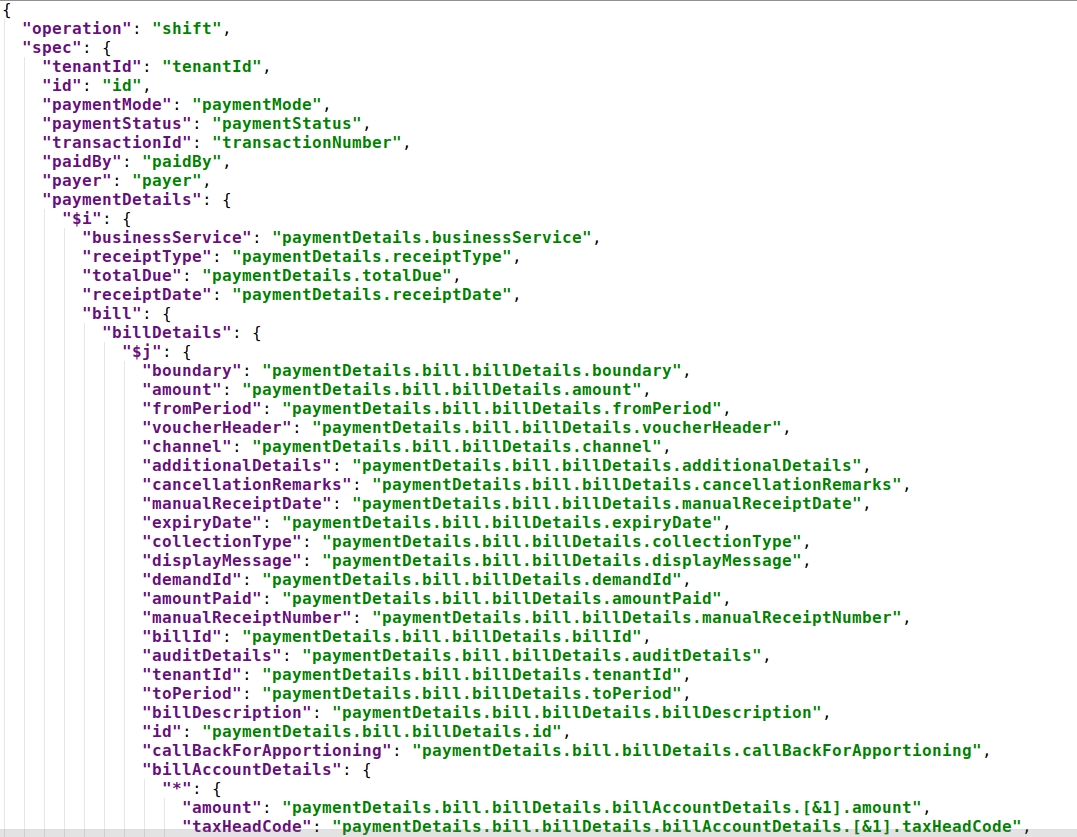
Use case:- JOLT Transformation Schema for collection V2
JOLT transformation schema for payment-v1 has been taken as a use case to explain the context collection and context version v2. The payment records are processed/transformed with the schema. The schema supports splitting the billing records into an independent new record. So if there are 2 bill items in the collection/payment incoming data then this results in 2 collection records in turn.
Click here for an example configuration
Here: $i, the variable value that gets incremented for the number of records of paymentDetails
$j, the variable value that gets incremented for the number of records of bill details.
Note: For Kafka connect to work, Ingest pipeline application properties or in environments direct push must be disabled.
es.push.direct=false
Below is the list of configurations
Chart API Configuration
Master Dashboard Configuration
Role Dashboard Mappings Configuration
Each Visualization has its own properties. Each Visualization comes from different data sources (Sometimes it is a combination of different data sources)
In order to configure each visualization and its properties, we have Chart API Configuration Document.
In this, Visualization Code, which happens to be the key, will be having its properties configured as a part of the configuration and are easily changeable.
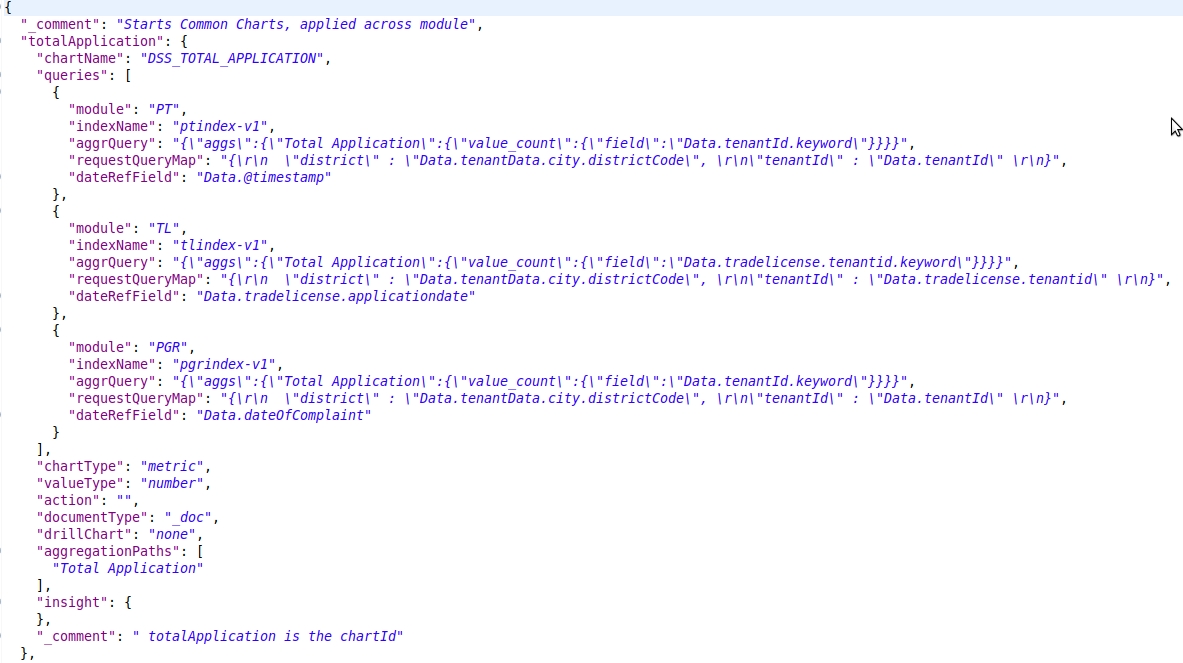
Click here for an example configuration
Key (e.g: totalApplication)
This is the Visualization Code. This key will be referred to in further visualization configurations. This is the key that will be used by the client application to indicate which visualization is needed for display.
chartName
The name of the Chart has to be used as a label on the Dashboard. The name of the Chart will be a detailed name. In this configuration, the Name of the Chart will be the code of Localization which will be used by Client Side
queries
Some visualizations are derived from a specific data source. While some others are derived from different data sources and are combined together to get a meaningful representation. The queries of aggregation which are to be used to fetch out the right data in the right aggregated format are configured here.
queries.module
The module / domain level, on which the query should be applied on. Property Tax is PT, Trade License is TL. If the query is applied across all modules, the module has to be defined as COMMON
queries.indexName
The name of the index upon which the query has to be executed is configured here.
queries.aggrQuery
The aggregation query in itself is added here. Based on the Module and the Index name specified, this query is attached to the filter part of the complete search request and then executed against that index
queries.requestQueryMap
Client Request would carry certain fields which are to be filtered. The parameters specified in the Client Request are different from the parameters in each of these indexed documents. In order to map the parameters of the request to the parameters of the ElasticSearch Document, this mapping is maintained
queries.dateRefField
Each of these modules has separate indexes. And all of them have their own date fields.
When there is a date filter applied against these visualizations, each of them has to apply it against their own date reference fields. In order to maintain what is the date field in which index, we have this configured in this configuration parameter
chartType
As there are different types of visualizations, this field defines as what is the type of chart / visualization that this data should be used to represent.
Chart types available are:
metric - this represents the aggregated amount/value for records filter by the aggregate es query
pie - this represents the aggregated data on grouping. This is can be used to represent any line graph, bar graph, pie chart or donuts
line - this graph/chart is data representation on date histograms or date groupings
perform - this chart represents groping data as performance-wise.
table - represents a form of plots and value with headers as grouped on and list of its key, values pairs.
xtable - represents an advanced feature of the table, it has additional capabilities for dynamic adding header values.
valueType
In any case of data, the values which are sent to plot might be a percentage, sometimes an amount and sometimes it is just a count. In order to represent them and differentiate the numbers from the amount from percentage, this field is used to indicate the type of value that this Visualization will be sending.
action
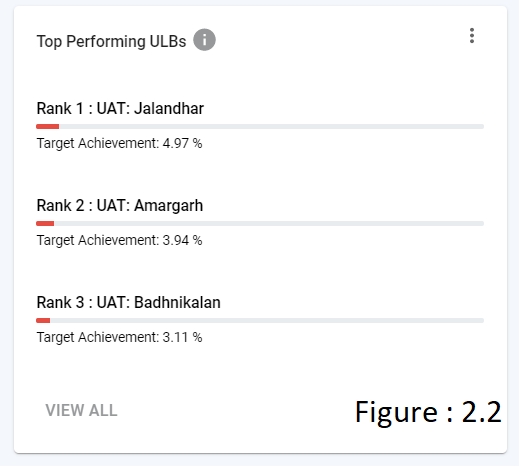
Some of the visualizations are not just aggregating on data source. There might be some cases where we have to do a post aggregation computation. For Example, in the case of Top 3 Performing ULBs, the Target and Total Collection is obtained and then the percentage is calculated.
In these kinds of cases, what is the action that has to be performed on that data obtained, is defined in this parameter.
documentType
The type of document upon which the query has to be executed is defined here.
drillChart
If there is a drill down on the visualization, then the code of the Drill Down Visualization is added here.
This will be used by Client Service to manage drill-downs
aggregationPaths
All the queries will be having Aggregation names in it. In order to fetch the value out of each Aggregation Responses, the name of the aggregation in the query will be an easy bet. These aggregation paths will have the names of Aggregation in it.
_comment
In order to display information on the “i” symbol of each visualization, Visualization Information is maintained in this field.
Master dashboard configuration defines the dashboards that are to be painted on the screen.
It includes all the visualizations, their groups, the charts and even their dimensions in terms of height and width.
Click here for an example configuration
name
Name of the Dashboard which has to be displayed as Page Heading
id
Unique Identifier of the Dashboard which should be used later for Querying each of these Visualizations
isActive
Active Indicator which can be used to quickly disable a dashboard if required.
style
Style of the Dashboard. Whether it should be a linear one or a tabbed one. This information is maintained in this parameter.
visualizations
The list of visualizations that are to be displayed in the Dashboard is listed out here.
visualizations.row
The row identifier for each Visualization are mentioned here
The name of an individual visualization is added here
visualizations.vizArray
The list of Charts within the Visualization is specified in this list.
Group of Charts is given an ID to have a placement on the Dashboard. This unique identifier is maintained in this field.
Group of Charts is given a name that can be displayed on the group on Dashboard in that row.
visualizations.vizArray.dimensions
Each of these group of charts is given a dimension based on which they are placed in a specific row in a dashboard
visualizations.vizArray.vizType
As there are multiple charts grouped into one visualization, the type of Visualization needs to be specified in order to indicate to the client application what goes inside each of these visualizations and charts inside them
vizType used for any other dashboards:- metric-collection, chart, performing-metric
metric-collection:- Used to specify the type as single or group of metric chart type
2. performing-metric:- Used perform chart type
3. chart:- Used chart type for pie, donut, table, bar, horizontal bar, line
vizType used for the Home page:- collection, module
collection: used in UI style as full width
2. module: used in UI style for specific width.
visualizations.vizArray.noUnit
visualizations.vizArray.isCollapsible
visualizations.vizArray.ref
The value types of these charts are different. Some are numbers, some are amounts, some are percentage.
In the case of amounts, there is a requirement to display in Lakhs, Crores and Units. In order to indicate the client application whether to display these units or not, we have this boolean to control that
The value type is for card/visualisation collapsible as boolean values.
This object contains url (as mandatory), logoUrl (optional), type(optional).
visualizations.vizArray.charts
The list of individual charts inside a Visualization Group is maintained in this array list
Individual Chart Number Identifier to indicate the uniqueness of Charts
Name of the Chart which can be a header label for Charts within a Visualization
visualizations.vizArray.charts.code
Code of the Chart is the indicator that has to be sent to Server Side to get the data for representing the Visualization.
visualizations.vizArray.charts.chartType
Type of Chart which has to represent the data result set that is obtained is specified here
chartType:- bar, horizontalBar, line, donut, pie, metric, table
visualizations.vizArray.charts.filters
Filters that can be applied to the Visualization and what are the fields which are filterable are mentioned here.
visualizations.vizArray.charts.headers
In some cases, there are headers which can be a title or additional information for the Chart Data which gets represented. This field is kept open to accommodate the information which can be sent along with the Chart Data in itself.
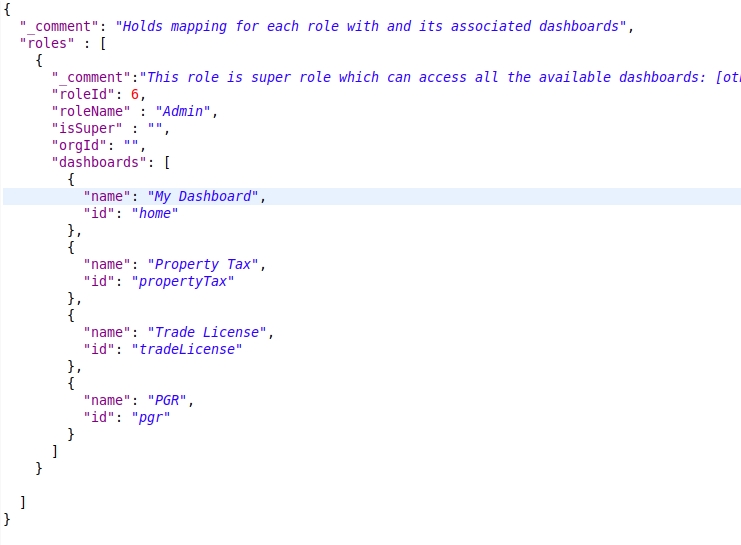
Role dashboard mapping ensures that each role is mapped against the dashboards that they are authorized to see.
Click here for an example configuration
roles
List of Roles that are available in the system
roles._comment
Role Description and comment on why does this role has an entry in this configuration and sums up the summary as to what are the things that are to be enabled.
roles.roleId
Unique Identifier of the Role for which Access is being given
roles.roleName
Name of the Role for which the access is being given
roles.isSuper
Boolean flag which defines whether the Role is a Super User or not
roles.orgId
Organization to which the Role belongs to
roles.dashboards
List of Dashboards that are enabled for the Role
Name of the individual Dashboard which has been enabled
Identifier of the individual Dashboard which has been enabled
To add a new role, modify the RoleDashboardMappingsConf.json (roles node) configuration file as given below.
Note: Any number of roles & dashboards can be added
Below as in Figure 9 is a sample to add a new role object, a new dashboard object.
To add a new dashboard, modify the MasterDashboardConfig.json (dashboards node) as shown below in Figure 10.
Note: dashboards array add a new dashboard as given below
To add new visualisations, modify the MasterDashboardConfig.json (vizArray node) as shown in Figure 11.
Note: vizArray is used to hold multiple visualizations.
To add a new chart, chartApiConf.json has to be modified as shown below. A new chartid has to be added with the chart node object.
Metric chart Sample as shown in Figure 12.
Pie chart Sample as shown in Figure 13.
Line chart Sample as shown in Figure 14.
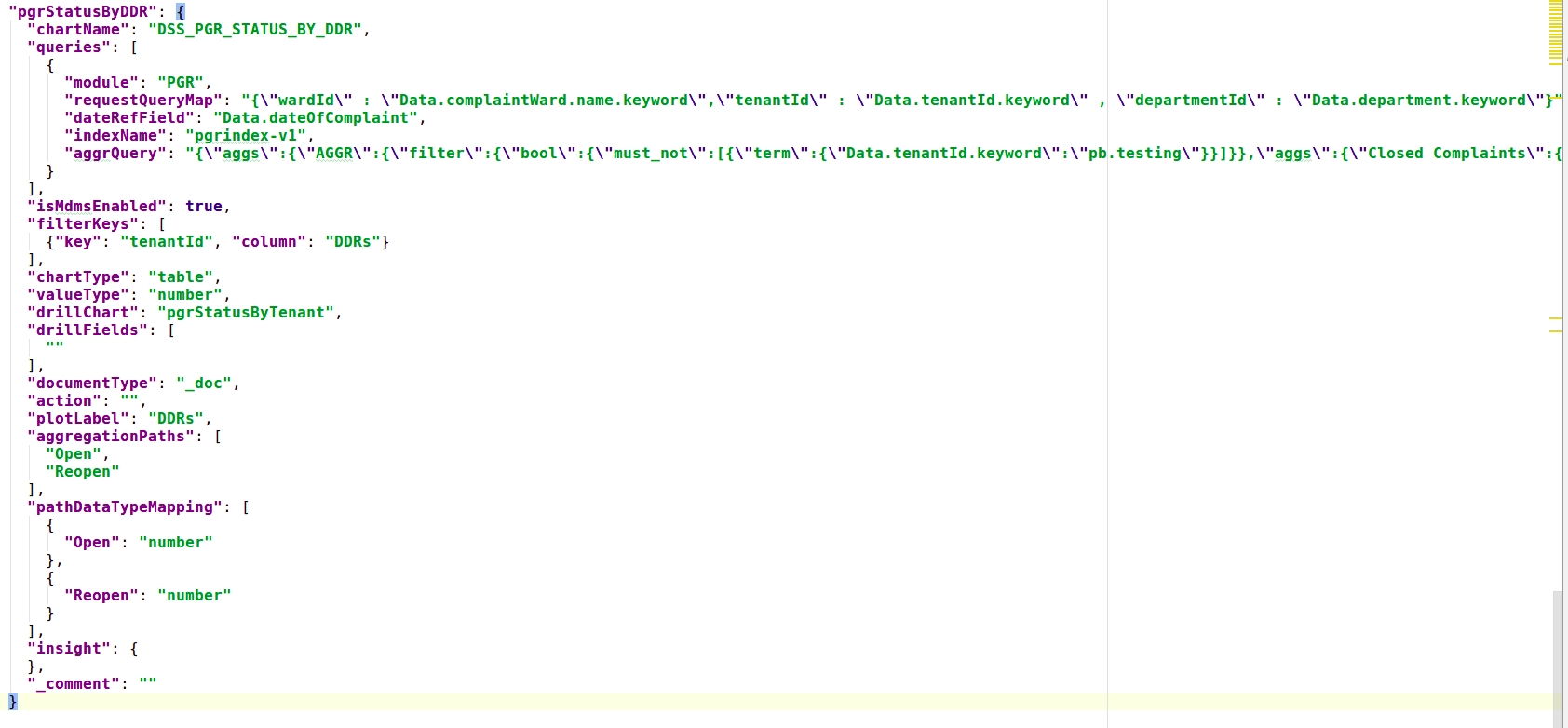
Table chart Sample: This chart is of 2 types - table and xtable.table (as shown in Figure 15.) Type allows the addition of aggregated fields as available in the query keys. To extract the values based on the key, aggegationPaths have to be added along with their data type as in pathDataTypeMapping.
xtable (as shown in Figure 16) type allows the addition of multiple computed fields with the aggregated fields added dynamically.
To add multiple computed columns, define the following params within computedFields []
actionName - (IComputedField<T> interface),
fields - [] names as existing in the query key,
newField - name to appear for the computation
https://github.com/egovernments/configs/blob/master/egov-dss-dashboards/dashboard-analytics/ChartApiConfig.json for the full configuration in detail.
Steps to create charts and visualise are:
Create/Add a chart in chartApiConf.json
Add a visualization for the existing dashboard in MasterDashboardConfig.json as defined above.
Or in order to create/add a new dashboard create the dashboard in MasterDashboardConfig.json and create a role in RoleDashboardConfig.json
Configuration Changes For DrillThroughs:
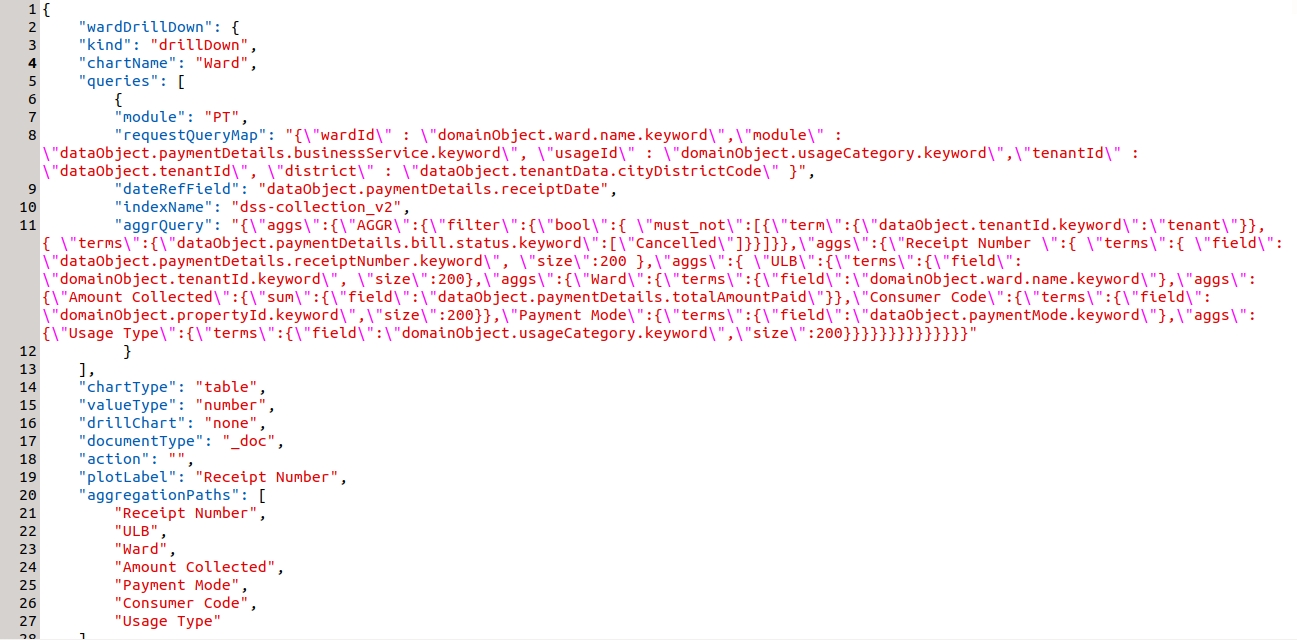
Example - drill through in ward table in the property tax dashboard.
wardDrillDown is the visualization code for PT Drill Down. The 'kind' attribute shows the type of visualization code. Apart from two things all the attributes are common.
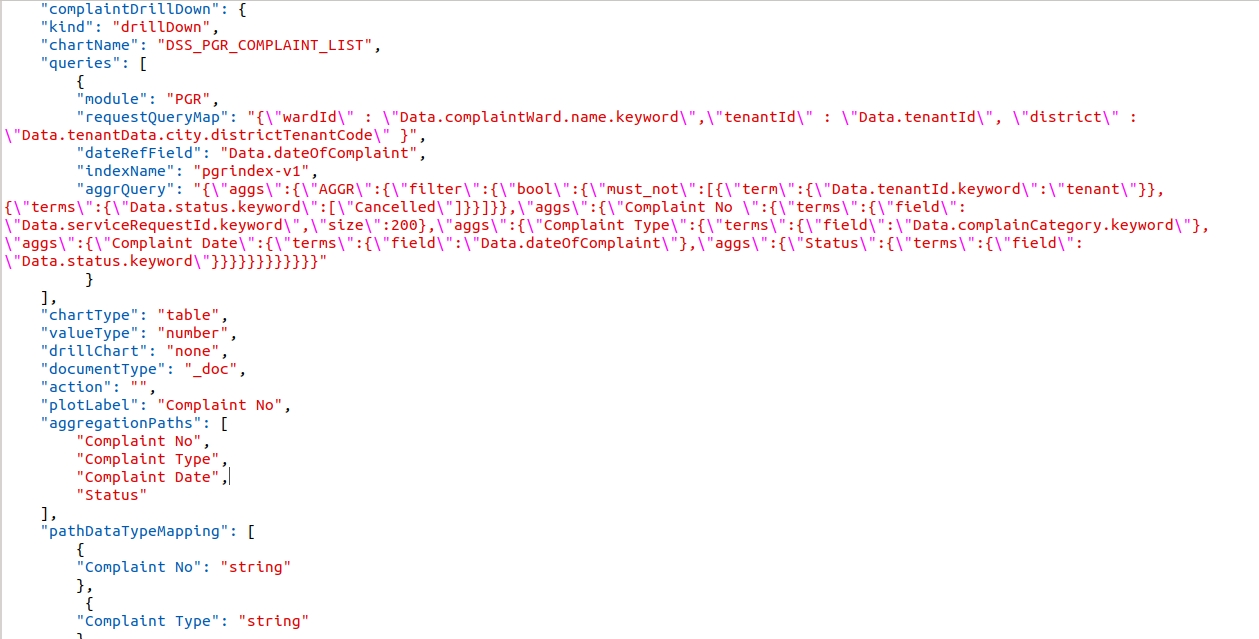
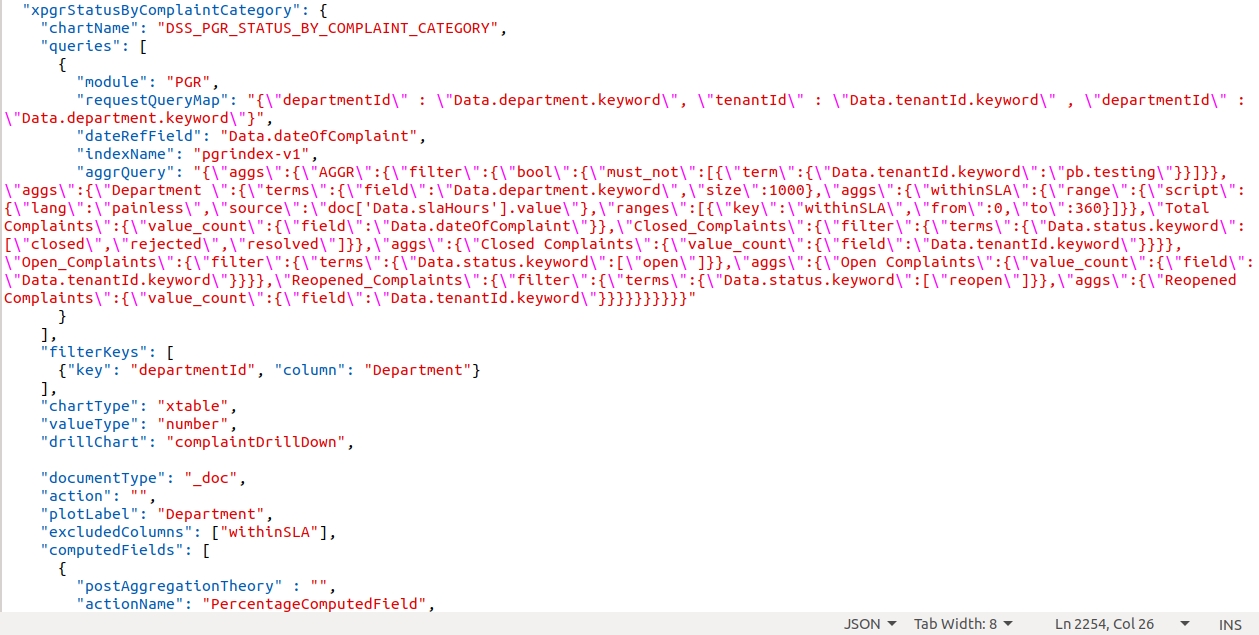
Example - Drill through in the ComplaintList table in the PGR Dashboard.
complaintDrillDown is the visualization code for PGR Drill Down.
The above complaintDrillDown visualization code is called in the drill chart parameter.
A decision support system (DSS) is a composite tool that collects, organizes and analyzes business data to facilitate quality decision-making for management, operations and planning. A well-designed DSS aids decision makers in compiling a variety of data from many sources: raw data, documents, personal knowledge from employees, management, executives and business models. DSS analysis helps organizations identify and solve problems, and make decisions.
Code Git Repos: https://github.com/egovernments/frontend/tree/master/web/dss-dashboard
State-Level Admin
Commissioner
Domain-Level Employee
There are three types of dashboards -
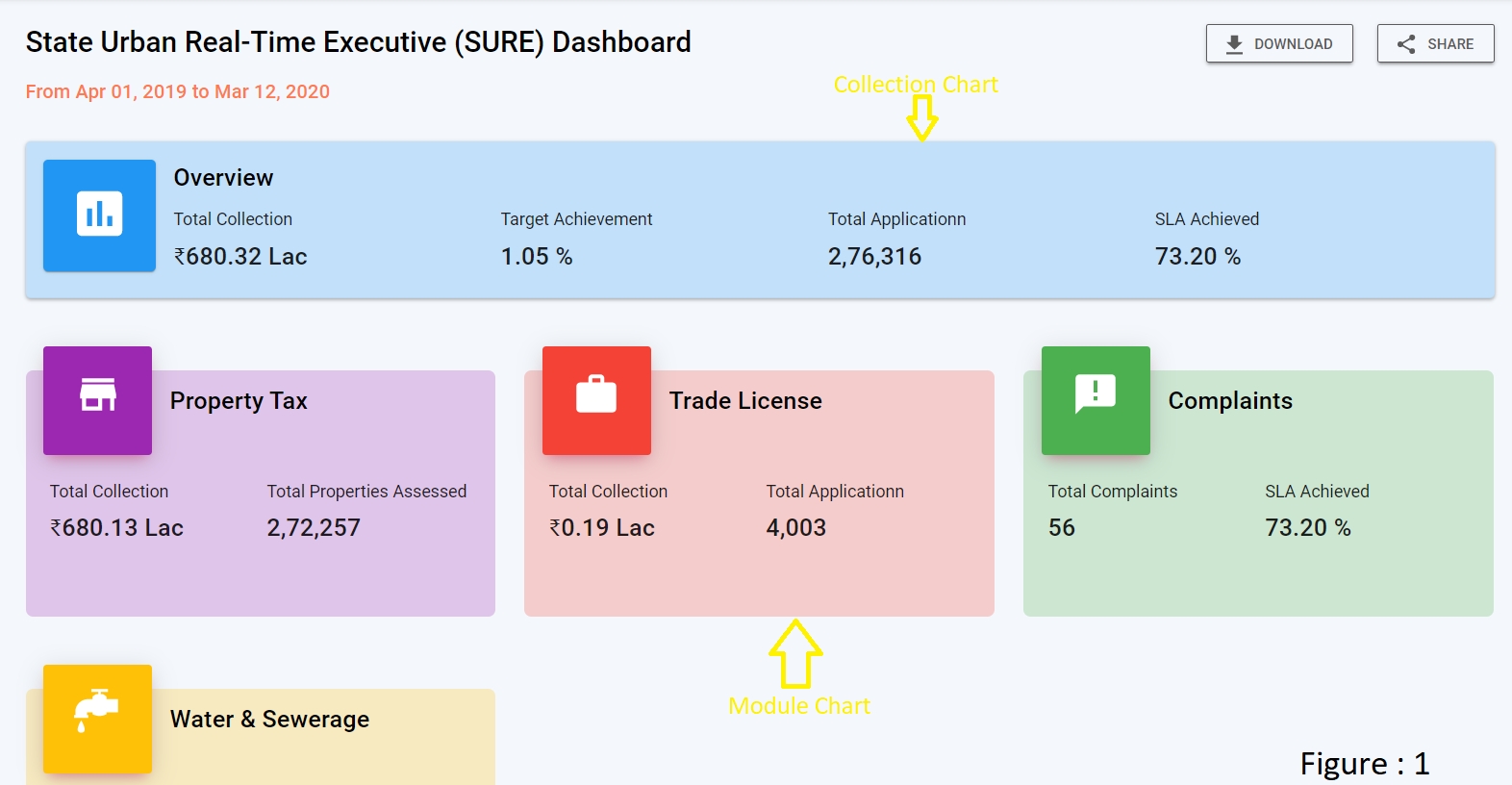
Home page (refer figure 1)
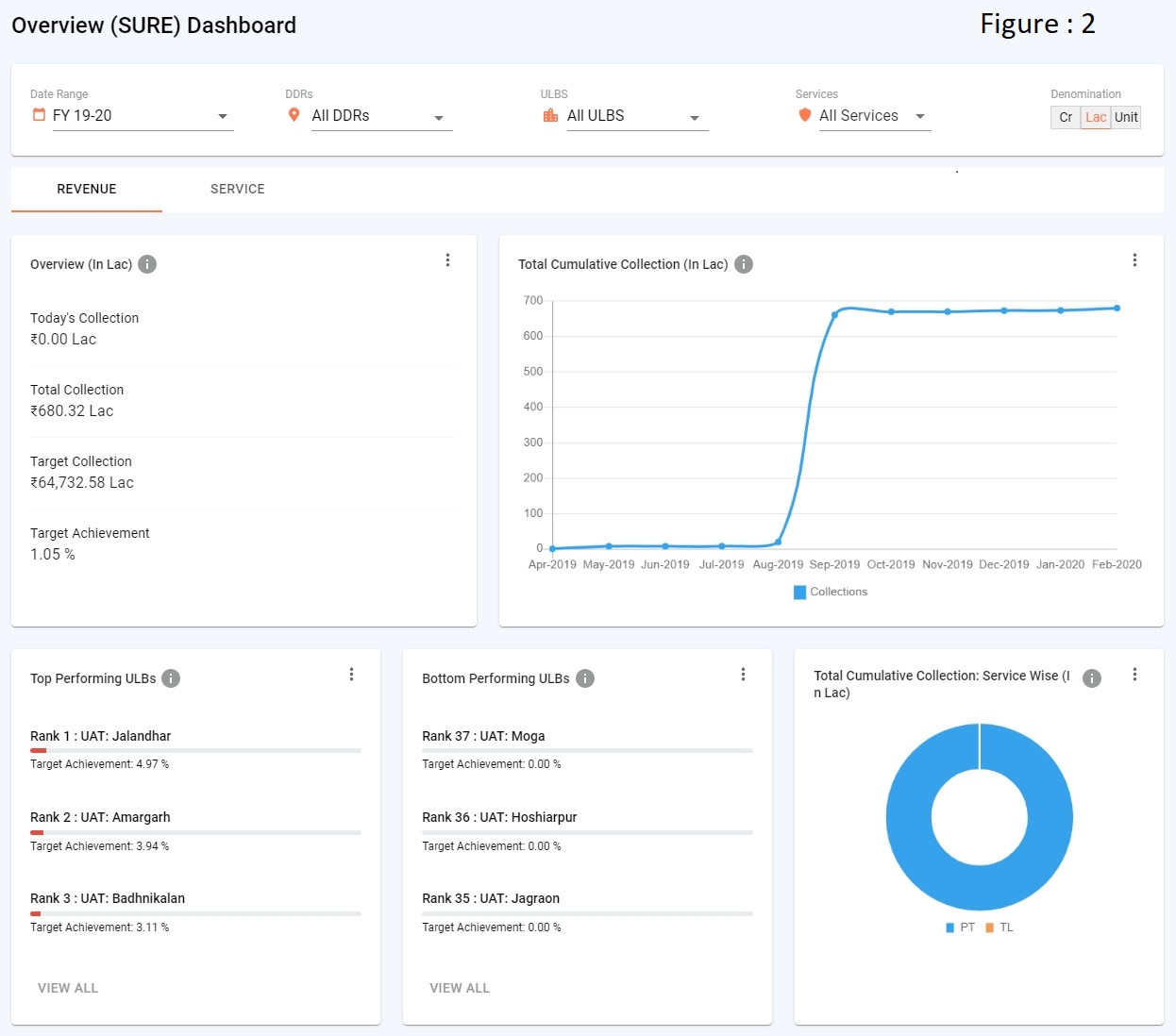
Overview page (refer figure 2)
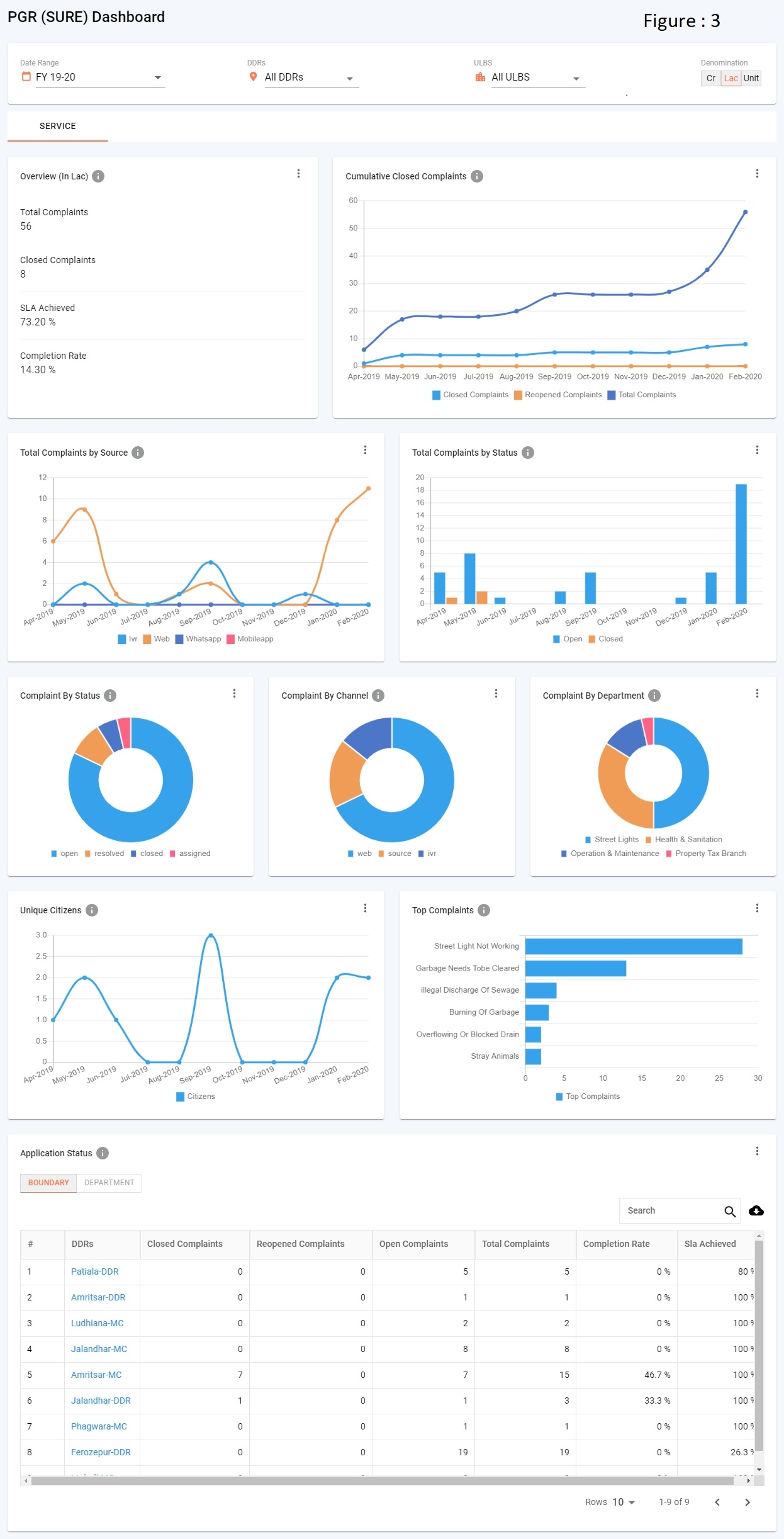
Module level dashboard (refer figure 3)
The home page contains multiple cards, each card is clickable.
There are two types of cards, i.e, the overview card and the module-level card.
The overview and the module level cards are differentiated by vizType,
Overview card: Clicking on the overview card navigates to the overview page. vizType for overview is a collection.
Module Level card: Clicking on the module level card navigates to the module level dashboard. vizType is a module (i.e Property Tax, Trade License etc).
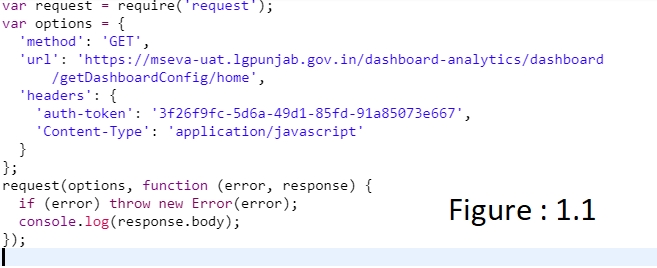
Request Payload for dashboardConfig
auth-token: authenticate the request and it fetches from a local storage key called “Employee.token”
DashboardConfig API Response
roleName: the type of user.
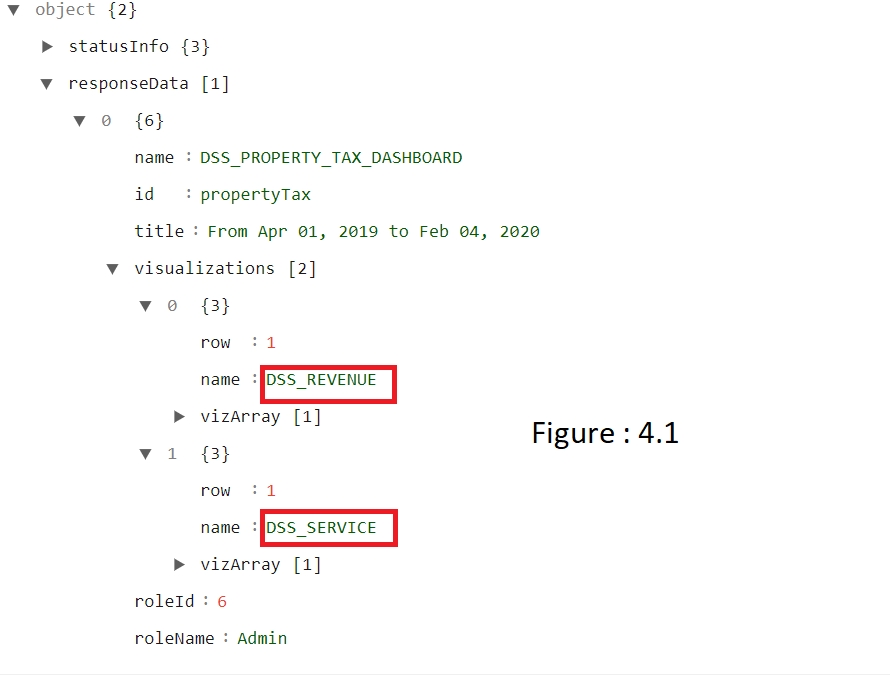
Visualisations: The key contains all configurations for displaying the visualisation like rows with charts etc please refer to figure 1.3.
In Figure 1.3, vizType key will define the module UI like
Collection chart & module chart refer figure 1
In dashboardConfig response, the visualisation key contains all rows & charts details (refer figure 1.3). Each row contains the visual details like name, vizType, noUnit, isCollapsible, charts etc (refer figure 1.3).
name - name of visualisation
vizType - type of visualisation like COLLECTION, MODULE, METRIC-COLLECTION, PERFORMING-METRIC, CHART
COLLECTION - The home page, contains the collection data (refer figure 1).
MODULE - The home page, contains the module-level data (refer figure 1).
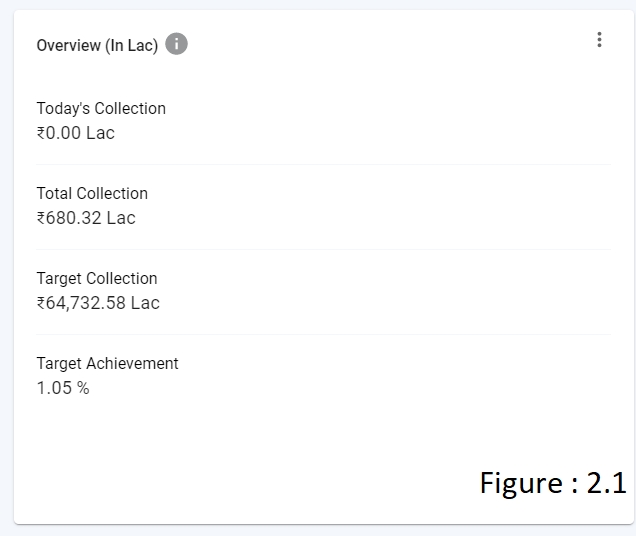
METRIC-COLLECTION - In Overview/Module Level Page, contains the collection data (refer figure 2.1).
PERFORMING-METRIC -In Overview/Module Level Page, contains the top/bottom performing data (refer figure 2.2).
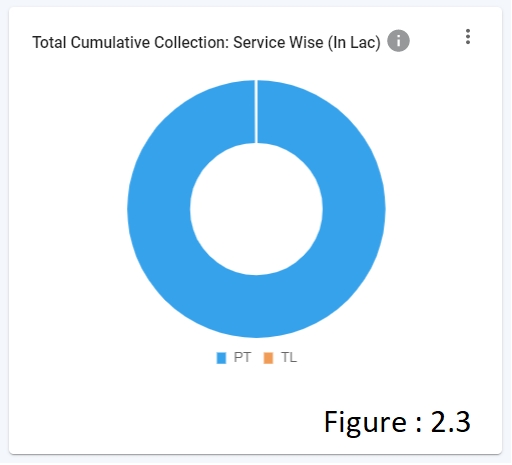
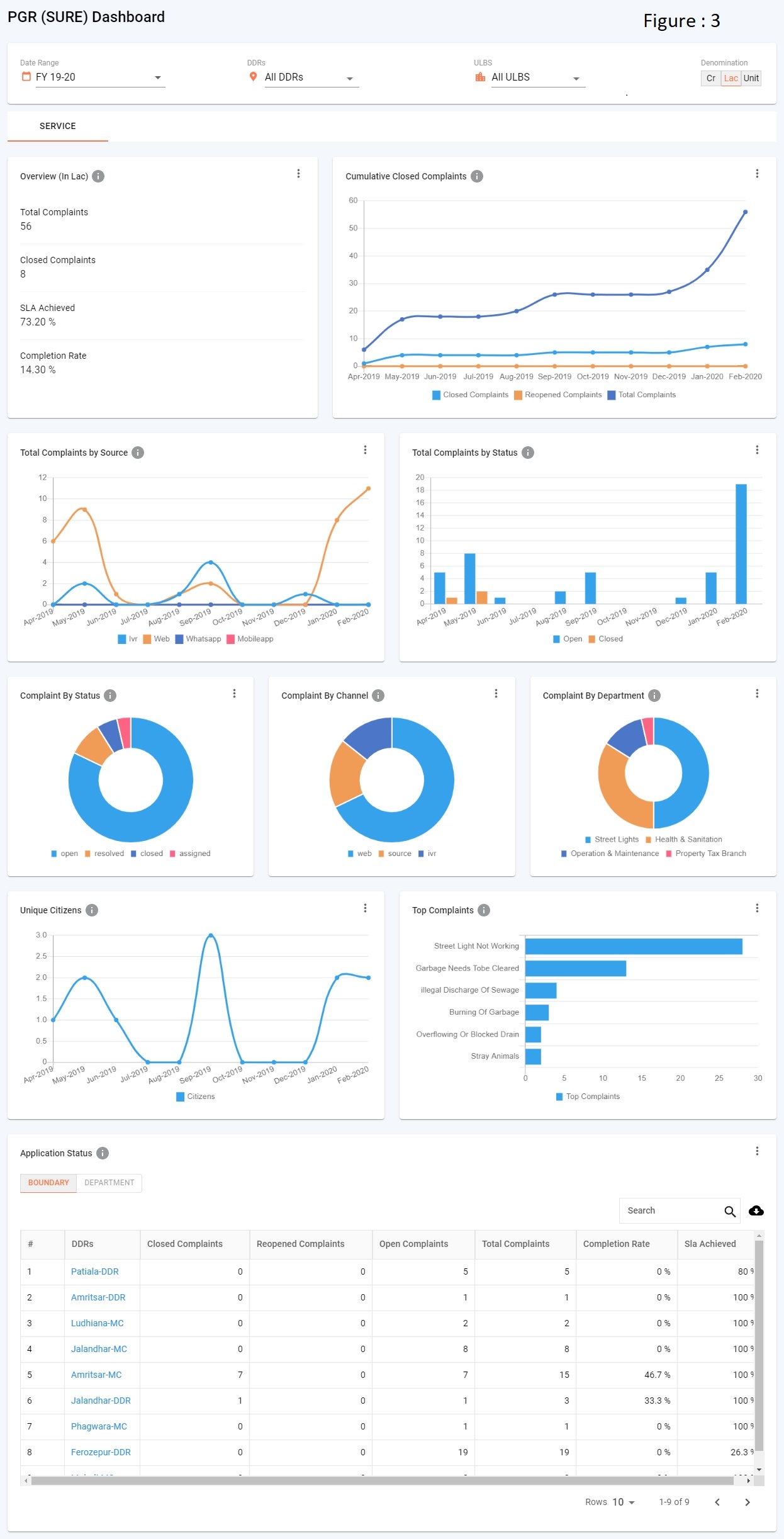
CHART - In Overview/Module Level Page, contains the below visualisations (refer figure 2.3 to figure 2.7).
PIE CHART (refer figure 2.3)
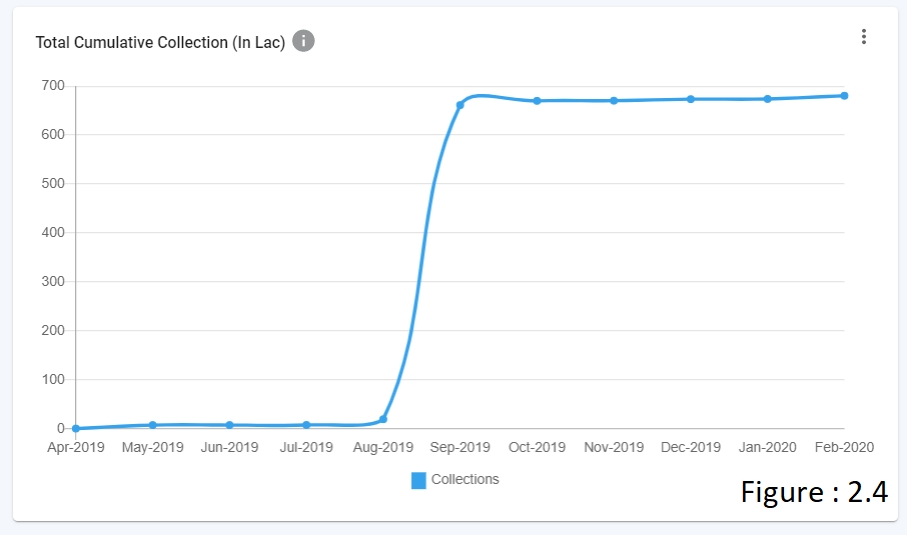
LINE CHART (refer figure 2.4)
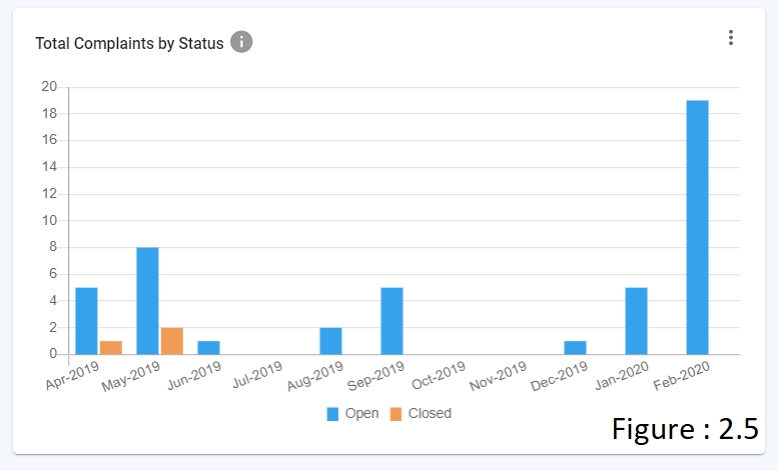
BAR CHART (refer figure 2.5)
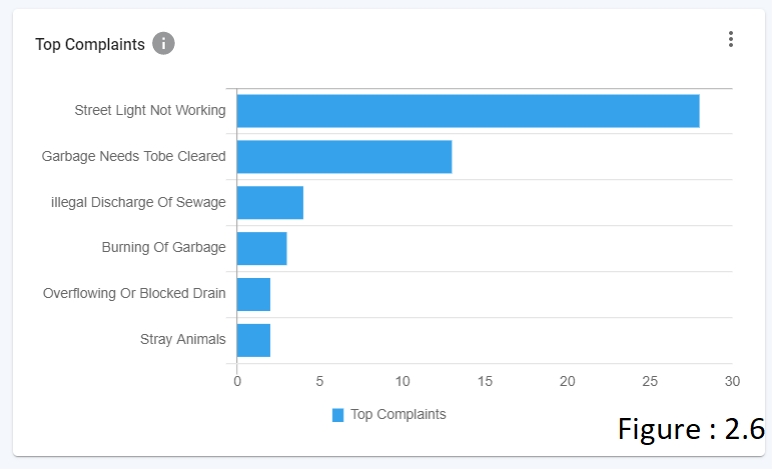
HORIZONTAL BAR CHART (refer figure 2.6)
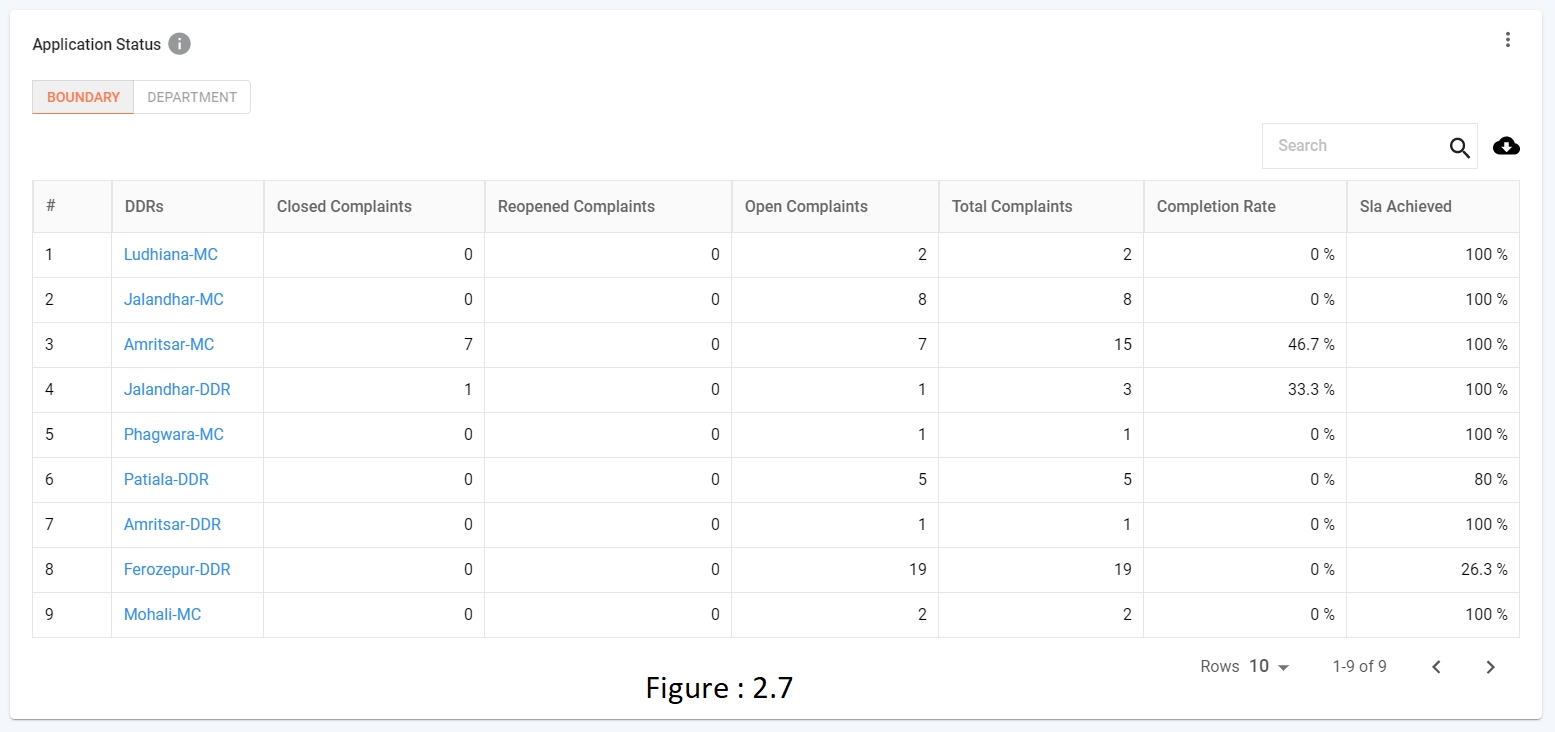
TABLE CHART (refer figure 2.7)
Visualisations
ULB dashboard contain different filters, i.e ULBs and Wards/Blocks. The data to the filters are loaded from MDMS API below - https://dev.digit.org/egov-mdms-service/v1/_search
Each ULB dashboard, overview dashboard and module-level pages contain different filters and are identified by roleName in configs API.
The Wards/Blocks filter is a dependable filter, which gets loaded on ULB selection.
In the ULB dashboard, the on-page ULB filter is applied across all the charts and for the performance chart, the default ULB filter is not applied.
Overview and all module level pages has a ULB dashboard.
GLOBAL Filters (refer to figure 2.8)
Filters are loaded from the MDMS API - https://dev.digit.org/egov-mdms-service/v1/_search. Filters are loaded on the basis of roleName.
Admin role: On the Module level page, Date, DDR and ULB filter are loaded.
On the Overview level page, Date, DDR, ULB and Service filter are loaded.
Commissioner role: On the Module level page, Date, ULB and Wards/Blocks filters are loaded.
On the Overview page, Date, ULB and Service filters are loaded.
Denomination filter: The Denomination filter has three options to display the amount and number in a particular format.
Crore
Lack
Unit
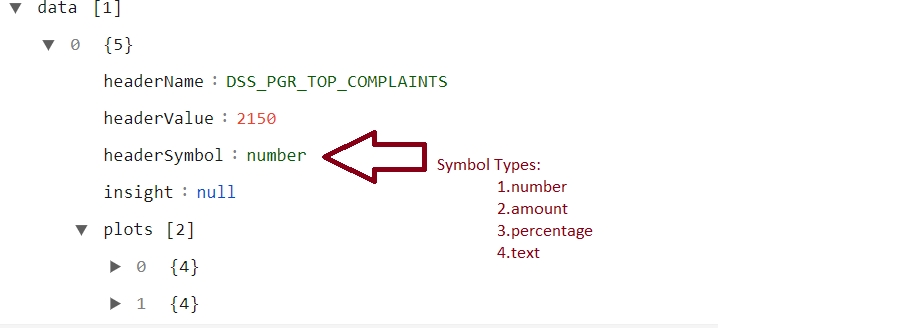
The denomination filter is not applied to the percentage and text (refer to figure 2.10). The type of data is identified by a symbol in the plots of charts API.
Custom Date Filter
If duration < 15 days, it displays data day-wise
If duration <= 30 days, it displays data week-wise
If duration >30, it displays data month-wise
Tabs
Currently, the dashboard contains two types of tabs -
Revenue (refer figure: 4.1)
Service (refer figure: 4.1)
Tabs are identified by name in visualisations of config API.
Table Chart with drill-down
Table chart visualisations have normal material UI data table features like search, sort etc.
In table response, if filter key & drillDownChartId contain any value users can drill-down the table.
Cards
Each card header is localised and has an info icon with a tooltip option that displays the header and can display a description.
The number of cards in a row and in a page is driven by the backend. The backend provides the row number to each card where it should be displayed.
Card contains option icon that enables users to either download images and or share images.
Image download and share user id from vizArray in order to differentiate each card in a page.
Download and Share (refer to figure 2.9)
Download offers two options - to download data as an image or a PDF.
Share: Share creates the Image/PDF and uploads it S3 using below API and returns file id - https://mseva-uat.lgpunjab.gov.in/filestore/v1/files
The file Id is fetched using the API - https://mseva-uat.lgpunjab.gov.in/filestore/v1/files/url
Each S3 image is shortened using the API - https://mseva-uat.lgpunjab.gov.in/egov-url-shortening/shortener
Configurations
Github link for config: https://github.com/egovernments/frontend/blob/master/web/dss-dashboard/src/config/configs.js
BASE URL: End point of REST API for dashboard.
FILE Upload: End point of REST API for file upload.
FETCH FILE: End point of REST API for file fetch.
MDMS: End point of REST API for fetch MDMS Data.
SHORTEN URL: End point of REST API for Shorten URL, which is used for share via Email / What's app.
CHART COLOR CODE: Color code object for all charts.
MODULE LEVEL: for global filters, which contains services name & filter key.
SERVICES: for global filter, service filter.
Upload Localisation Keys
code: pre-defined key for back-end.
message: message contains the value for the key.
module: rainmaker-dss
locale: contains locale data
for more details eGov team to be documented
Module name: rainmaker-dss
NPM Module Used - https://github.com/egovernments/DIGIT-OSS/blob/master/frontend/mono-ui/web/dss-dashboard/package.json
Steps to setup DSS in Local
Step 1: Run as independent, switch to dss-dashboard folder
Step 2: Get the below details from the environment website and update the localstorage in the browser.
Employee.tenant-id Employee.user-info Employee.token Employee.module Employee.locale localization_en_IN locale
Step 3: Run Yarn install and yarn start to start working on dss in local setup.
DSS Features Enhancements V2: DSS Features Enhancements V2 Technical Document for UI
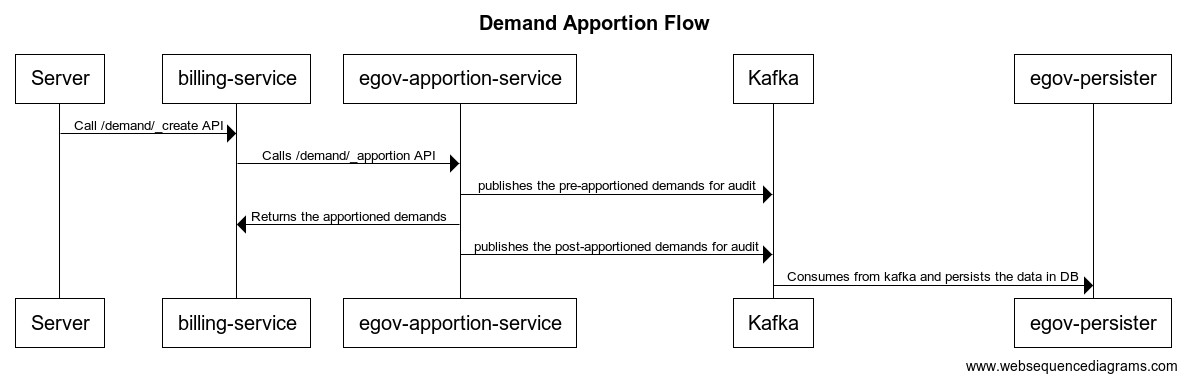
Apportion service is used to apportion the amount paid against a bill among the different tax heads based on the implemented algorithm. The default algorithm uses the order of the tax head to apportion the tax head with the lowest order apportioned off first and the highest order tax head apportioned last.
Before you proceed with the documentation, make sure the following pre-requisites are met -
Java 8
Kafka server is up and running
egov-persister service is running and has apportioned persister config path added to it
PSQL server is running and a database is created to store apportion audit data
Apportion payment in tax heads of bill
Apportion advance amount in tax heads of demand during demand creation
egov.apportion.default.value.order
If set to true will apportion of the negative amount first irrespective of tax head order
Deploy the latest version of egov-apportion-service
Add apportion persister yaml path in persister configuration
There is no separate configuration required. The TaxHead master that is configured in the billing service is only used
Any payment service which wants to divide the paid amount into different tax head buckets can integrate with apportion service.
Apportions amount in tax heads
To integrate, the host of egov-apportion-service should be overwritten in the helm chart
/apportion-service/v2/bill/_apportion should be called to apportion the bill
/apportion-service/v2/demand/_apportion should be called to apportion the advance amount in demands
Collection Service
Billing Service
API Swagger Documentation
/apportion-service/v2/bill/_apportion
/apportion-service/v2/demand/_apportion
(Note: All the APIs are in the same postman collection therefore the same link is added in each row)
Technical documentation detailing migration steps
This specifies the migration steps which are specific to the payment index.
Step 1: Adding a target index - Add index name dss-payment_v2 as below:
In kibana, dev tools, apply the below command
PUT dss-payment_v2
{} // add mapping file content here. mapping.json as attached below
Note: This name should be as the value present in ingest es.index.namemapping.json24 May 2021, 11:15 AM
Step 2: Optional changes required in Ingest application properties
Ingest pipeline application properties contain es.direct.push supposed to be set true for testing.
1.
es.direct.push
true
the transformed data will be pushed to ES index directly.
2.
es.direct.push
false
the transformed data will be lying at egov-dss-ingest-enriched topic
Step 3: Run migration Api, which migrates the data from the source index to the target index.
Method
End Point
Body
POST
{host}/dashboard-ingest/ingest/migrate/paymentsindex-v1/v2
{"RequestInfo":{"authToken":"2ba70924-1bba-4a9b-b55d-2e9471bf3081"}}
2.
CURL
Note: After migration, ensure dss-payment_v2 data has been populated and is available.
In kibana, dev tools verify using below command
V2 Technical Document for UI
This release for DSS focuses on improving user experience and the ability given to the user to get deeper insights using drill-through and comparison indicators in tables.
The release includes the following features:
Breadcrumbs for better navigation
Drill through options in tables and charts
Comparison indicators in Table
In addition to the left navigation panel, the addition of breadcrumbs is also useful to provide a better sense of the current page insight. It is also very much helpful for mobile navigation. The user can navigate using the breadcrumbs by clicking on the required parent menu.
Technical Implementation Details
It Works based on the Current Route URL and previous Route URL
File Details - https://github.com/egovernments/frontend/blob/master/web/dss-dashboard/src/Breadcrumbs.js
The ability provided in DSS to configure the drill through for required options in tables as well as charts. The drill through options is useful in configuring the required hierarchy of data set. This helps users to go up to 'N' levels to get deeper insights
Technical Implementation Details:
Drill down/drill through in tables, is based on the drillDownChartId and filter.
Here chart id is used for the subsequent call to fetch the next table along with the applied/selected filters.
File Details - https://github.com/egovernments/frontend/blob/master/web/dss-dashboard/src/components/Charts/TableChart.js
Drill throughs in piecharts:
It is similar to the drill-down in tables. Here drill through in piecharts are based on the drillDownChartId field in the parent piechart.
File Details - https://github.com/egovernments/frontend/blob/master/web/dss-dashboard/src/components/Charts/DonutChart.js
Providing better insights about the metric performances of different dimensions, a comparison indicator is required inside data tables comparing usually with a different time range (last year/last month) and what is percentage change with time.
Technical Implementation Details:
Comparison with the previous year's data in every table data uses the same request object by changing the time range to the previous year/month/week.
File Details - https://github.com/egovernments/frontend/blob/master/web/dss-dashboard/src/components/Charts/TableChart.js
The following method along with parameters is used to fetch the previous year's data.
After receiving last year's data it is compared with the current year's data. The comparison is shown as insight data. The comparison logic is present in uiTable.js -
TimeFilter
The current time component is not very intuitive and user-friendly. So a new library react-date range is used to enhance the time filter.
File Details - https://github.com/egovernments/frontend/blob/master/web/dss-dashboard/src/components/common/DateRange/index.js
Event Duration Graphs
Ability to generate graphs showcasing time spent between multiple events like average turnaround time, complaint assigning time, etc.
A DSS_EVENT_DURATION_GRAPH is added in the PGR config
/localization/messages/v1/_search
1531
SUPERUSER,EMPLOYEE,CITIZEN,GRO,DGRO,
/egov-mdms-service/v1/_search
954
LOA_CREATOR,SUPERUSER,WO_CREATOR,AE_CREATOR,WORKS_MASTER_CREATOR,
/dashboard-analytics/dashboard/getDashboardConfig/propertytax
1892
STADMIN
/dashboard-analytics/dashboard/getDashboardConfig/home
1889
STADMIN
/dashboard-analytics/dashboard/getDashboardConfig/tradelicense
1893
STADMIN
/dashboard-analytics/dashboard/getDashboardConfig/pgr
1894
STADMIN
/dashboard-analytics/dashboard/getDashboardConfig/ws
2010
STADMIN
/dashboard-analytics/dashboard/getChartV2
1890
STADMIN, EMPLOYEE
Migration details from v1 to v2
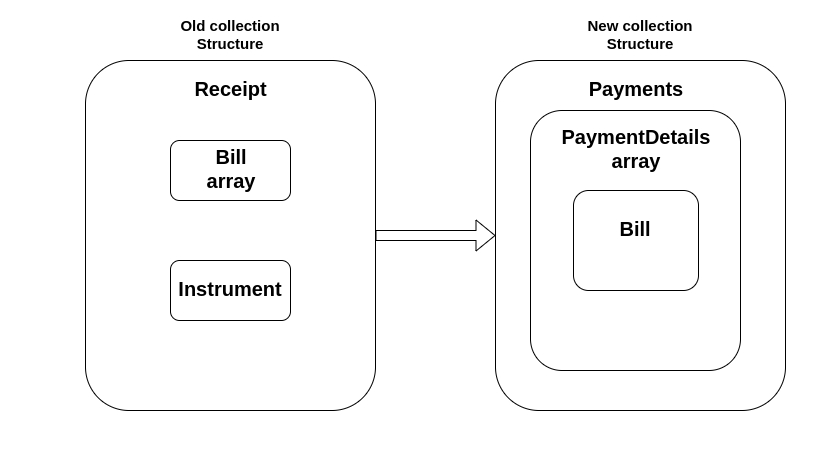
According to the new collection service, which follows the payment structure for storing information about payments and payment details, it is necessary to migrate the old collection structure into the new payment structure.
In the old collection service, for every transaction, the receipt number is generated on the bill detail level. Since the bill contains multiple bill details each transaction is mapped to multiple receipt numbers. So after payment of a single bill, multiple receipt numbers are generated. The mapping of the transactions to the receipt number changed in the new collection service.
In the new collection service, the receipt number is generated at the bill level. For each bill transaction, one receipt number is generated. So every bill for a consumer code and business service has one receipt number.
The records from tables egcl_receiptheader, egcl_receiptdetails, egcl_instrument, egcl_instrumentheader need to be transferred into tables egcl_payment, egcl_paymentdetail, egcl_bill, egcl_billdetial, egcl_billaccountdetail.
For smooth data transactions, the record from the old receipt is mapped according to the payment structure. The new payment response can be formed with receipt data.
The table below provides the mapping between receipt and payment structure with some remarks.
Payments.Id
---
Set as UUID
Payments.tenantId
Receipt.tenantId
Payments.totalDue
---
Total due for payment is calculated by subtracting totalAmount from bill and amount from Receipt.instrument
Payments.totalAmountPaid
Receipt.instrument.amount
Payments.transactionNumber
Receipt.instrument.transactionNumber
Payments.transactionDate
Receipt.receiptDate
Payments.paymentMode
Receipt.instrument.instrumnetType.name
Payments.instrumentDate
Receipt.instrument.instrumentDate
Payments.instrumentNumber
Receipt.instrument.instrumentNumber
Payments.instrumentStatus
Receipt.instrument.instrumentStatus
Payments.ifscCode
Receipt.instrument.ifscCode
Payments.additionalDetails
Receipt.Bill.additionalDetails
Payments.paidBy
Receipt.Bill.paidBy
Payments.mobileNumber
Receipt.Bill.mobileNumber
If mobileNumber from Receipt.bill is null it has to set with some value e.g: “NA”
Note: Payments.mobileNumber should not be null
Payments.payerName
Receipt.Bill.payerName
Payments.payerAddress
Receipt.Bill.payerAddress
Payments.payerEmail
Receipt.Bill.payerEmail
Payments.payerId
Receipt.Bill.payerId
Payments.paymentStatus
--
Based on paymentMode from Payment, the paymentStatus is set.
If paymentMode is ONLINE or CARD then paymentStatus is set to DEPOSITED otherwise it is set to NEW
Payments.auditDetails.createdBy
Receipt.auditDetails.createdBy
Payments.auditDetails.createdTime
Receipt.auditDetails.createdTime
Payments.auditDetails.lastModifiedBy
Receipt.auditDetails.lastModifiedBy
Payments.auditDetails.lastModifiedTime
Receipt.auditDetails.lastModifiedTime
Payments.paymentDetails.Id
---
Set as UUID
Payments.paymentDetails.tenantId
Receipt.tenantId
Payments.paymentDetails.totalDue
---
Total due for paymentDetails is calculated by subtracting totalAmount from bill and amount from Receipt.instrument
Payments.paymentDetails.totalAmountPaid
Receipt.instrument.amount
Payments.paymentDetails.receiptNumber
Receipt.receiptNumber
Payments.paymentDetails.manualReceiptNumber
Receipt.Bill.billDetails.manualReceiptNumber
Payments.paymentDetails.manualReceiptDate
Receipt.Bill.billDetails.manualReceiptDate
Payments.paymentDetails.receiptDate
Receipt.receiptDate
Payments.paymentDetails.receiptType
Receipt.Bill.billDetails.receiptType
Payments.paymentDetails.businessService
Receipt.Bill.billDetails.businessService
Payments.paymentDetails.additionalDetail
Receipt.Bill.additionalDetail
Payments.paymentDetails.auditDetail
---
auditDetail for paymentDetail is same as payment auditDetail
Payments.paymentDetails.billId
---
Based on id in egbs_billdetail_v1 table billId is extracted,Where id in egbs_billdetail_v1 is Receipt.Bill.billDetails.billNumber
Payments.paymentDetails.bill
---
Based on the billid, tenantid and service the bill is search by calling the Billing service API and set it to Payments.paymentDetails.bill
Payments.paymentDetails.bil.billDetails.amountPaid
Receipt.instrument.amount
For each amountPaid in billDetails, its value is set from Receipt.instrument.amount
After the creation of the payment response with receipt data, it is pushed into the Kafka topic “egov.collection.migration-batch”. The persister inserts the payment data into tables - egcl_payment, egcl_paymentdetail, egcl_bill, egcl_billdetial, egcl_billaccountdetail.
Indexer config for the legacy data index and new payments.
https://github.com/egovernments/configs/blob/master/egov-indexer/payment-indexer.yml
persister config -
These need to get promoted before initiating the migration process. Migration happens through an API call, add role-actions based on your requirement. Otherwise, port-forwarding will work.
Endpoint: /collection-services/payments/_migrate?batchSize=100&offset= Body: { "RequestInfo": { "apiId": "Rainmaker", "action": "", "did": 1, "key": "", "msgId": "20170310130900|en_IN", "ts": 0, "ver": ".01", "authToken": "a6ad2a1b-821c-4688-a70e-4322f6c34e54" }
In case of any failure and restarting migration, take the value of offset and tenantId printed in the logs and resume the migration process.
/collection-services/payments/_migrate?batchSize=100&offset=200&tenantId='pb.tenantId'
Collection-service build:- collection-services-db:9-COLLECTION_MIGRATION-e9701c4
A decision support system (DSS) is a composite tool that collects, organizes and analyzes business data to facilitate quality decision-making for management, operations and planning. A well-designed DSS aids decision-makers in compiling a variety of data from many sources: raw data, documents, personal knowledge from employees, management, executives and business models. DSS analysis helps organizations identify and solve problems, and make decisions.
The Swagger API for the backend is below
Swagger API for ingest
The target upload file template is given below -
__All content on this page by eGov Foundation is licensed under a Creative Commons Attribution 4.0 International License.
DIGIT is India's largest open-source platform for Urban Governance. It provides API-based access to government functions enabling the government to provide facilities via integration with relevant service players. This document provides the details of how system integrators enable bill collection facilities to customers using DIGIT as the governance platform. It outlines the integration approach with Billing and Collections services to enable fetching bill dues to citizens and recording their payments into the system.
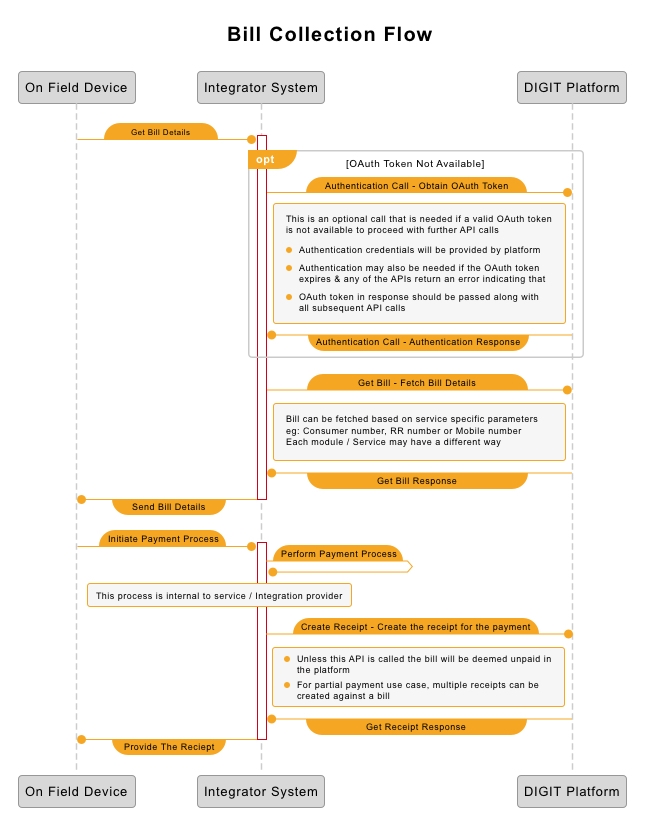
DIGIT is completely API driven and allows for data exchange with disparate systems using REST API calls. Most functional APIs are protected resources that can be accessed after proper authentication with the platform. The platform also checks for the right level of access for given credentials. A bill collection flow -
Authenticate with DIGIT
Get citizen bill using a service-specific query
Record the payment details against the bill
Optional - Get payment API to fetch the receipt details
The in-field team of the system integrator makes the calls to the integrator's own system (or a standard system like BBPS). Integration with DIGIT follows a server-to-server approach where the backend system of the integrator makes these calls to the DIGIT platform as per requirement. The diagram below depicts the high-level flow of calls between on-field devices like PoS to the integrator backend (Integrator System) and from the backend of the DIGIT integrator to DIGIT (DIGIT Platform).
Note: The process of calling payment API results in a receipt creation.
DIGIT uses Swagger 2.0 as its API standard and all its APIs are documented in Swagger. Wherever needed this document provides a link to our API documentation online. An example of typical request/response snippets necessary for integration is provided below in the respective sections.
DIGIT is a multi-tenanted system - hence all APIs in DIGIT except tenantid are passed either in the query param or RequestBody (Please refer to detailed API documentation as indicated in sections below). The tenantid represents the modular operating unit for the operation of an API, e.g. in a municipal governance use case. A tenantid represents one ULB. Your platform contact will help you access the configured list for your use case.
Authentication API also expects tenantid (your platform contact will help you identify the one to use). Based on the role as an integrator the OAUTH token in response can be used for unit/ULB level tenants in subsequent API calls (meaning you may not need one authentication per unit/ULB level tenant).
Authentication
To ensure data privacy and security, transactional APIs in DIGIT are protected under authentication. System integrators are requested to contact the respective state authority to get the necessary OAUTH tokens required to access the APIs.
Note: Apart from the userid/password, the system may enforce IP-based access control in which case the integrator may be required to share the IP or range of IPs from which the request will originate.
Use the API below to generate the access token based on the credentials provided. Given below is an example of the request and response. The OAuth token to be used from the response is highlighted in bold.
Request Snippet
Response Snippet
2. Fetching Bill
DIGIT allows the integrators to fetch the bills for citizens using the consumer number of the respective service (e.g. Water charges, Property Service, Trade License).
Note: Different services may have different notions of consumer number, e.g. for Water Charges consumer number signifies the "Connection number" while for Property it is the "Property Id".
For some services, DIGIT also provides the facility to fetch bills by mobile number.
Note: A bill search by mobile number may return multiple bills across services and may not return bills from services that do not support mobile-number-based search.
To support the partial payment use case each bill in the response of the fetch bill API indicates whether it allows partial payment and if yes, the minimum amount to be paid.
To fetch a bill from DIGIT, make sure that the OAuth token is generated as per the Authentication section above. Post that use the following API to fetch the bill -
Choose Billing Service from the dropdown.
Go to the Bill section of BillingService.
Go to the Bill tab.
3. Make Payment
Once the bill is fetched from the DIGIT system, the system integrator is expected to relay it back to the Field Device. The integrator is expected to Initiate and collect the payment based on government preference indicated in the bill (can it be partially paid and if so the minimum amount etc.) and citizen's preference of payment instrument etc.
Once the payment is successfully done in the integrator's system, the integrator is expected to register the payment in DIGIT using the Payment Create API.
Note: A bill is considered unpaid/partially paid by DIGIT till appropriate receipts are created using this API - which means that a subsequent fetch of the bill, till this API is called, returns the original bill
DIGIT expects a receipt (result of calling payment API) to be created against the bill number returned in the fetch bill API.
Note: A receipt needs to be created for each bill. Therefore, if a total payment represents multiple bills - one receipt creation per bill is expected (DIGIT supports multiple receipt creation in a single call).
To create a receipt in DIGIT, make sure that the OAuth token is generated as per the Authentication section above. Post that use the following API to create the receipt -
Choose Collection Service from the dropdown.
Go to Payment.
Go to Make Payment.
All content on this page by eGov Foundation is licensed under a Creative Commons Attribution 4.0 International License.
__All content on this page by eGov Foundation is licensed under a Creative Commons Attribution 4.0 International License.
__All content on this page by eGov Foundation is licensed under a Creative Commons Attribution 4.0 International License.
All content on this page by eGov Foundation is licensed under a Creative Commons Attribution 4.0 International License.
curl -X POST -H 'cache-control: no-cache' -H 'content-type: application/json' -H 'postman-token: d83fc136-116d-265f-3b83-ea41e3d5bb57' -d '{"RequestInfo":{"authToken":"2ba70924-1bba-4a9b-b55d-2e9471bf3081"}}'
__All content on this page by eGov Foundation is licensed under a Creative Commons Attribution 4.0 International License.
__All content on this page by eGov Foundation is licensed under a Creative Commons Attribution 4.0 International License.
__All content on this page by eGov Foundation is licensed under a Creative Commons Attribution 4.0 International License.