The page assumes that the deployment of the central instance will happen in a Kubernetes-based environment independent of whether it’s a cloud-based or a bare metal deployment with a Kubernetes-based orchestrator. This page lists all types of services available in a DIGIT SAAS package and the steps to deploy, implement, and add a new service.
Namespace/deployment-space - refers to the Kubernetes namespace or the equivalent by establishing access restrictions.
State/Tenant - A state is a separate entity whose applications and data are separated from the rest by namespaces and schemas in the database.
Backbone Services - The backbone services include Kafka, Redis, and Elastic stack. The number of deployments and the namespace where the services will be deployed are taken care of by the deployment manager itself.
State Deployment space - Namespace - In DIGIT SAAS, the private application/deployment space (namespace in K8s & schema in DB) is provided for different tenants (states) when they onboard, the steps to create and provide the same are mentioned in the following document.
Central/Shared Services - In DIGIT SAAS, each new tenant is given a separate namespace, but most use some unmodified out-of-box services provided by DIGIT deployed in a shared space known as the central namespace. These sets of services include some of DIGIT’s core services and registries. Among the services mentioned some can never be modified by the state (tenant) actors and some can be modified. In case of any modification, the services should be deployed in their own space.
The above-mentioned services cannot be modified by the state actors and should only be deployed in the central/shared namespace.
The services that are by default deployed and run in the state namespaces whether there are modifications or not. Since they have functionalities that are directly related to the specific requirement of the state.
These services can be divided into multiple categories -
The DIGIT applications require different types of config setup, they are as follows the MDMS data, persister, indexer, pdf, report, searcher and internal gateway.
The MDMS data is required for the Master data management service to supply the data required by other modules to perform their basic validation and verify the validity of the data. The prescribed format of the same can be found in the application setup. Since the application is deployed in all the namespaces central and state. Each deployment will need its own GitHub repo.
Central MDMS - central MDMS repo
State 1 MDMS - state1 MDMS repo
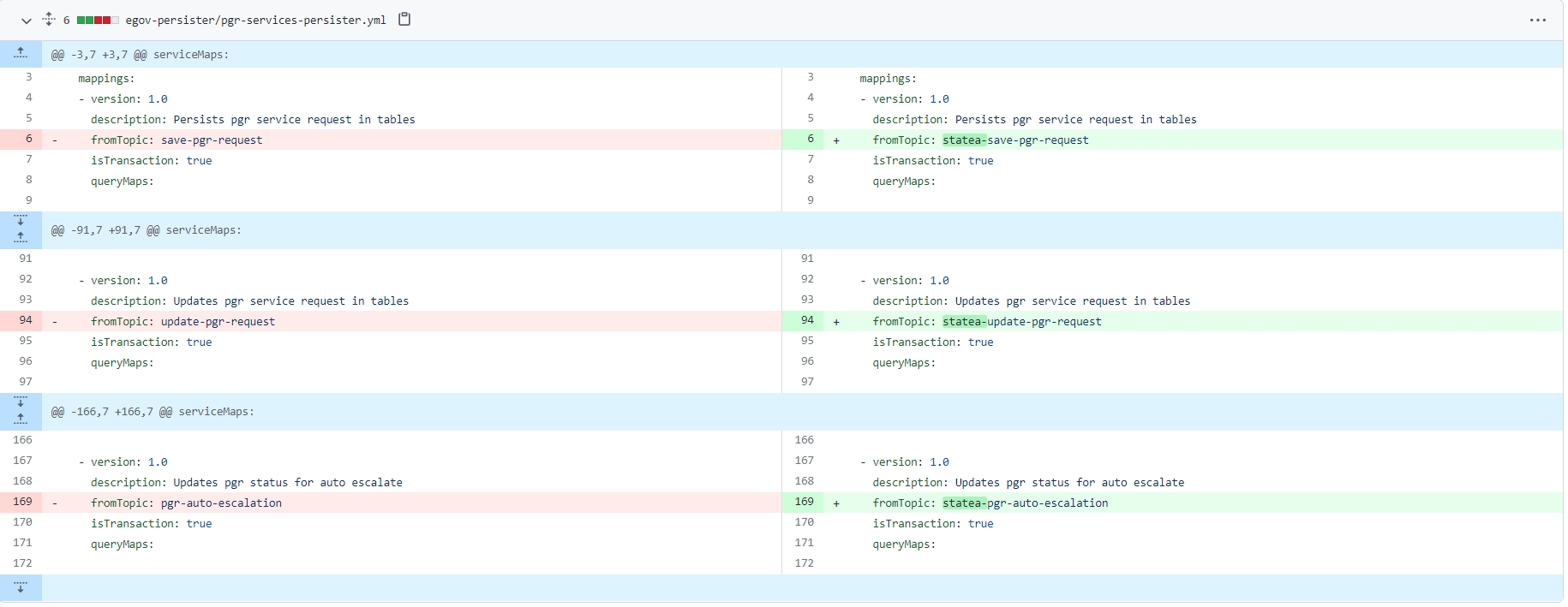
The persister and indexer configuration for all states should be added in a single GitHub repo in the same branch. Since both applications run in a single place. Each state deployment will have to modify their KAFKA topic names with a prefix of their state schema name.
save-property
state1-save-property
state2-save-property
update-property
state1-update-property
state2-update-property
The pdf configs have to be added in a separate repository since the format of pdfs printed will change with each different tenant.
The configs of report and searcher have to be added in the same GIT repo and same branches as the persister and indexer. The additional change that needs to be done here is that their URL should be appended with state schema names like the topic names with persister config.
reportName: AssetImmovableRegister
state1_AssetImmovableRegister
state2_AssetImmovableRegister
- name: billswithaddranduser
state1_billswithaddranduser
state2_billswithaddranduser
The internal gateway config should be added to the central git config repo since the app is deployed in the central namespace.
The development of any service in DIGIT should be based on this development guide.
The following library versions are a minimum requirement before any service can be made central instance compatible.
Changes to pom.xml
Add Tracer 2.1.1 and above
Services-common 1.1.0 and above
MDMS-Client 0.0.4 and above
ENC-Client 2.04 and above
The following document helps to make multi-environment applications (Services which will run in the DIGIT namespace but store their data in state-specific namespaces of DB based on tenant-id) central instance compatible. These services include the likes of -
Billing-service
Collection-service
workflow-service
egov-apportion-service
egov-hrms
All the municipal registries
Property-services
TL-services
PGR-services
bpa-services
echallan-services
firenoc-services
land-services
noc-services
sw-services
ws-services
Any service that needs to share its data among multiple DB schemas can be added to the above category.
Certain services in the Central-instance will only be deployed in the central (DIGIT) namespace but their data needs to be stored in different schema belonging to different state namespaces. The migrations of foretold services need to be run in all Required schemas (for instance: namespaces that want to make use of the centrally deployed services). To enable the above functionality the following changes are required.
Migrate.sh
This file is needed for building migration docker image is located in the DB folder of resources. eg: property-services/src/main/resources/db/migrate.sh. Update the file with the following contents:
values.yml
The DB configuration is by default provided in the common values.yml file in the helm chart and need not be edited in normal scenarios. Since we are injecting the multiple schema list for app-specific purposes all the DB-migration ENV variables should be overridden in the app-specific values.yml file.
#Values.yml of the specific service before multiple schema changes
#Values.yml of the specific service after multiple schema changes.
Only the - name: SCHEMA_NAME variable needs to be added and other fields can be copied from the common values.yml as it is without any changes. The above file contains an if-else condition with two new variables
The "property-ismultischema-enabled" Boolean value to check if the feature is enabled and "property-schemas" to derive the value from respective environments YAML. This example of two variables should be named differently based on service-name to avoid conflicts.
Environments.yml
In the respective environment’s file add the two new variables, one for the if condition and the other field for actual values under the respective service names. Lines 6 and 7 are the sample values provided here.
eg :
Any services that could potentially be commonly used by all environments in the central instance (refer to Multi Schema Service List for details).
Application.properties variables to be added.
state.level.tenantid.length=2 State-level tenant value will be picked from the full tenant-id separated by the '.' dot. once the tenant-id is separated by a dot the resulting array of sizes given above will be considered state level.
is.environment.central.instance=true
Declares whether the environment in which the service is deployed belongs to a central-instance kind of setup.
The both above said variable has to be overridden in the values YAML file of the respective service to pick up the values from the environment.
The host of the state-specific services referred by this service should be changed to the internal gateway host for tenant-based(namespace) redirection.
Sample values YAML file to refer to the above-said changes
If this service allows the search of data without tenant-id then the following validation should be added to all the search APIs belonging to the service. searches without state-level tenant-id (as described by this variable - state.level.tenantid.length) will render the application useless, so the following is mandatory
Update the Kafka producer in the service with the following code to enable the service to post to a tenant (namespace) specific topic based on the tenant-id.
Replace all the table names in the queries present with the {schema} placeholder
Add the following Schema replacer utility method and use the same to replace all queries with the respective schema.
Change the persister config to alter the Kafka topic names for the configs belonging to your respective multi-schema service. The Kafka topic name should be appended with the schema name of the respective state schema.
Whether a service is going to be deployed in a central instance or not, it should follow and integrate with the central instance util library of common services.
Refer to the common update document 3.1 General update for services to be Central-Instance compatible.
Make use of centralInstanceUtil class to perform any tenantId manipulations. Manual manipulation of tenantId is to be avoided for common purposes like getting state-level tenantId, and state-specific Kafka topics. Read the following methods from MultiStateInstanceUtil class found in the common-services package and make use of them as mentioned in the document.
New environment variables are to be added mandatorily for environments.
The environment should be set to false when the current server is not for multi-state(non-central-instance), disabling and enabling this make the methods in the multiStateUtil class behave as required.
The state-level tenant length describes what part of the whole tenantId represents the state part. for eg: in tenantId “in.statea.tenantx”. in.statea represents the state part so the value will be 2.
The schema index position points to the substring of the tenantId whose value represents the schema name of the database for the given state.
values.yaml - the full updated sample file can be found here
2.9 release master migration document
This page contains the changes related to core and municipal services along with the MDMS, DevOps and configuration setups required to accommodate multi-tenancy. Browse through the details below to learn more about the Central Instance.
Refer to SAAS Guidelines for Central Instance to find additional information.
The service-request module is required for the surveys to work. Follow the steps given below:
Add the Service-request module
Add the new persister file: service-request-persister
Add the Helm chart
Configure the build
Make the role action-mapping changes in the MDMS
Click on the Job-builder once the above steps are complete.
Restart the following services: egov-accesscontrol, egov-mdms-service, egov-persister
Deploy the service-request module build
For further details on how to use Citizen-feedback APIs refer to the Citizen Feedback service.
Create the Citizen Feedback Service definitions (as mentioned in the above Citizen Feedback Service document) for modules and flows as per requirement before using it on the UI.
Note: Service definition creation is a backend task that requires sending an API request using tools like Postman. This task is typically performed once during the initial setup process.
Refer to KPIs: Pendancy, Citizen Feedback and Pt-SLA changes and make changes as per the document.
Restart dashboard analytics with Cluster-configs.
Central Instance:
Find the details for prepping the UI build for a new instance.
UI build preparation for a new instance
Citizen Consent Form:
This feature allows citizen users to give their consent at the time of logging in.
Add this MDMS file
Documentation: a. Refer to Citizen Consent Form b. Restart MDMS and deploy the latest front-end builds.
Citizen Feedback:
A functionality that allows users to provide the user facility to submit feedback/ratings at the end of the service.
Add the MDMS file available here: https://github.com/egovernments/egov-mdms-data/blob/QA/data/pb/common-masters/RatingAndFeedback.json
In the provided configuration, the parameter headerByRating is utilized to specify the value for the star condition, along with the corresponding message to be displayed on the UI screen. The enabledScreensList parameter is used to indicate the specific flows where the Citizen feedback screen will be presented, allowing citizens to provide reviews.
The rating component is utilized for displaying star ratings on the citizen feedback screen. You can locate this component within the micro-ui-internals folder on the following GitHub link: Rating.js.
Documentation
a. Refer to Citizen Feedback Documentation for more details.
b. Restart MDMS and deploy the latest front-end builds.